







The conventional wisdom around Postgres-backed queues is that they don't scale. To handle a large workload, you can't use Postgres, but instead need a dedicated queueing system like RabbitMQ + Celery or Redis + BullMQ. There's a reason people say this: queues really are a demanding workload for Postgres. At scale, thousands of workers are polling your queues table at the same time, creating contention and churning indexes. But with the right optimizations, Postgres can handle it. In this blog post, we'll show how we optimized Postgres-backed queues at scale, achieving 30K workflow executions per second across thousands of servers.
Lesson 1: (Re-)Discovering SKIP LOCKED
To make Postgres-backed queues work at all, the first problem to solve is contention between multiple workers dequeueing the same workflows. At a high level, the way Postgres-backed queues work is that clients enqueue workflows by adding them to a queues table, and workers dequeue and process the oldest enqueued workflows (assuming a FIFO queue). Naively, each worker runs a query like this to find the N oldest enqueued workflows, then dequeues them:
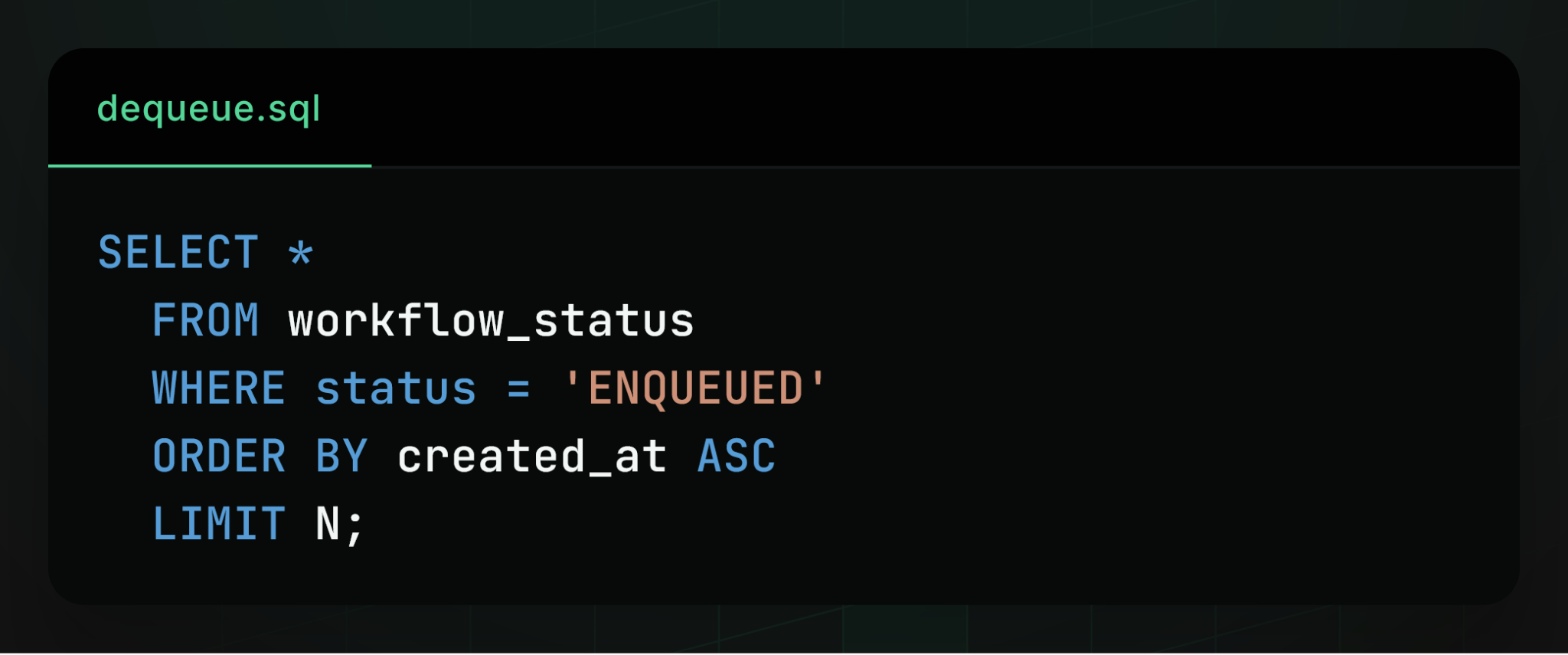
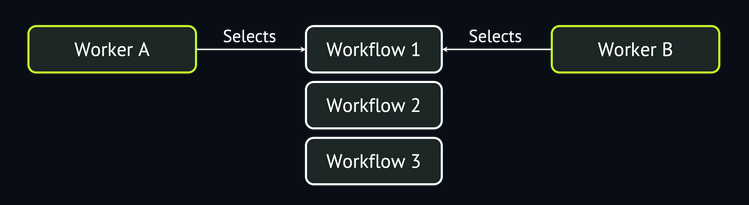
As soon as multiple workers run this query concurrently, contention arises. Every worker sees the same oldest queued workflows and attempts to dequeue them at the same time. But each workflow can only be dequeued by a single worker, so most workers will fail to find new work and have to try again. At a large scale, this contention creates a bottleneck in the system, limiting how rapidly tasks can be dequeued.
Fortunately, Postgres provides the primitive required to solve this problem: locking clauses. Here's an example of a query using FOR UPDATE SKIP LOCKED:
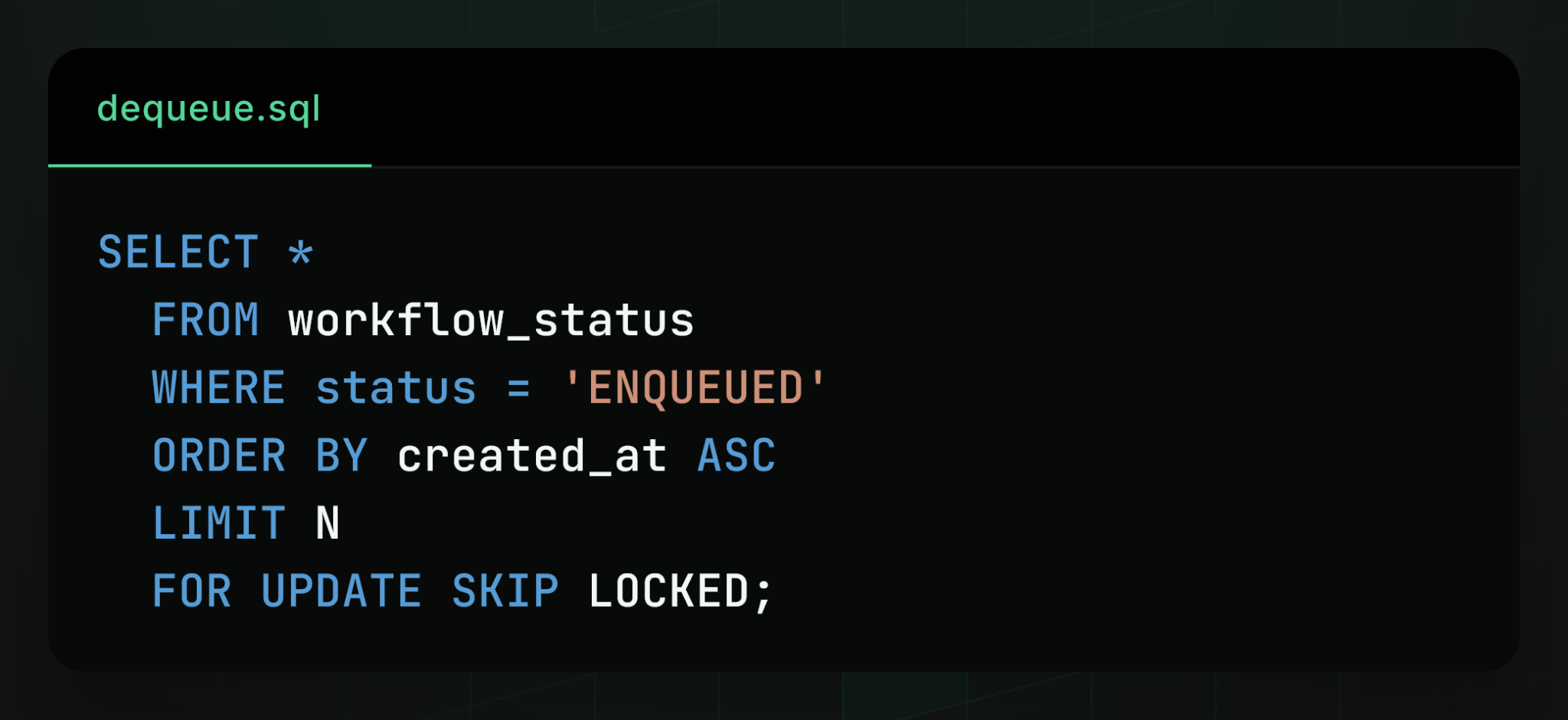
Selecting rows in this way does two things. First, it locks the rows so that other workers cannot also select them. Second, it skips rows that are already locked, selecting not the N oldest enqueued workflows, but the N oldest enqueued workflows that are not already locked by another worker. That way, many workers can concurrently pull new workflows without contention. One worker selects the oldest N workflows and locks them, the second worker selects the next oldest N workflows and locks those, and so on.
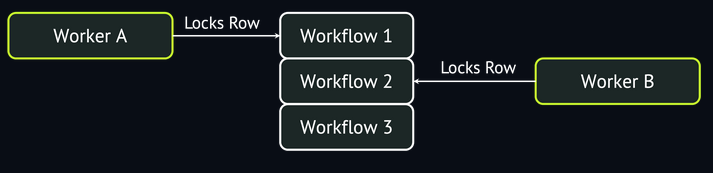
Locking clauses make Postgres-backed queues possible (which is why SKIP LOCKED is one of those old Postgres tricks that keeps getting rediscovered). Without them, contention between workers prevents scaling beyond ~100 workflows per second. With them, Postgres can scale far further, but achieving that scaling requires more optimizations.
Lesson 2: Mind the Transaction Isolation Levels
While locking clauses improve performance dramatically, we soon reached another contention-related bottleneck: at scale, dequeue operations would frequently fail with Postgres “Serialization Failure” exceptions and need to be retried. When dequeueing more than ~1000 workflows per second, the majority of dequeue operations encountered serialization failures, creating a performance bottleneck.
The culprit turned out to be Postgres transaction isolation levels. The dequeue transaction originally ran at REPEATABLE READ so it could support global queue limits like "run at most N workflows concurrently across all workers." Enforcing those global limits requires workers to share a globally consistent view of queue state, and REPEATABLE READ (in Postgres) guarantees that a transaction will operate on a fixed “snapshot” of the database as it was when the transaction started, and will not “see” the effects of concurrent transactions that complete while it is running.
The problem is that REPEATABLE READ becomes expensive at high concurrency. If multiple workers concurrently modify overlapping rows, Postgres aborts one of them with a serialization failure. At scale, workers spent more time retrying transactions than processing workflows.
The key realization was that the largest queues rarely used global flow control. At scale, users usually prefer local limits, such as "run at most 10 workflows per worker", which do not require cross-worker coordination.
So we made the isolation level conditional:
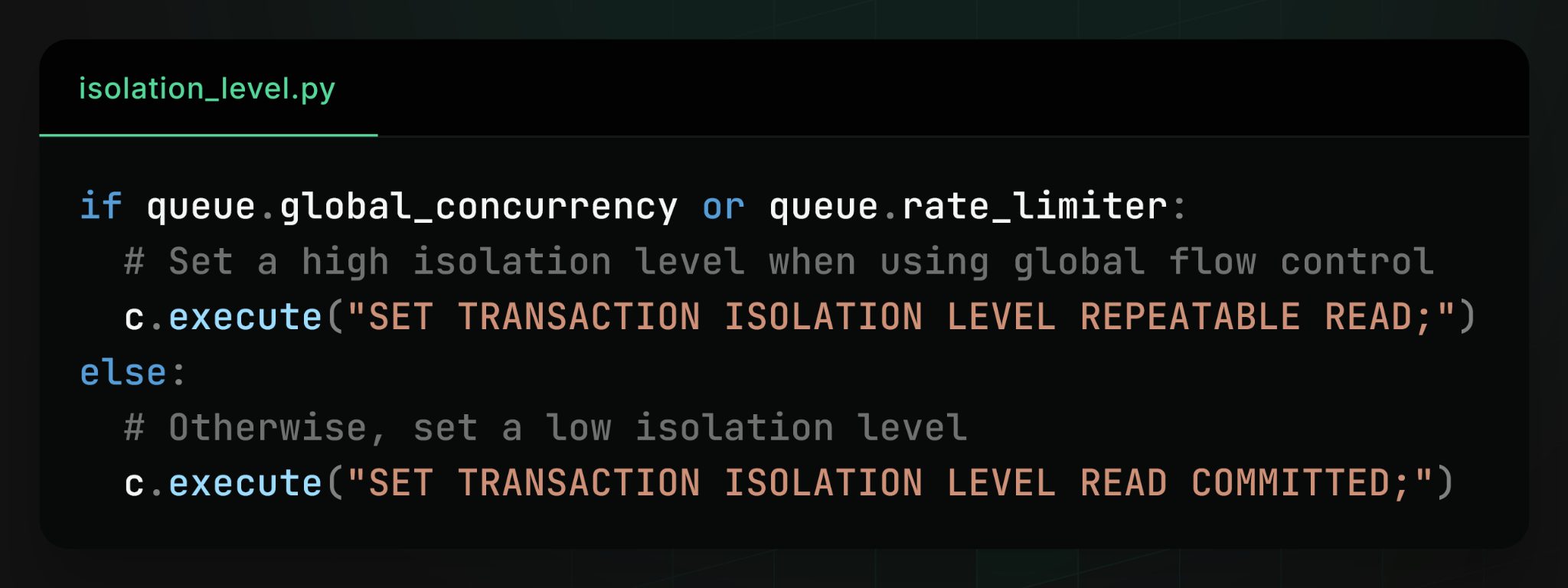
Queues with global flow control continue using REPEATABLE READ, while queues without it use READ COMMITTED, which eliminates serialization failures entirely and dramatically improves throughput.
Lesson 3: Indexes Aren't Free
With both locking clauses and a lower isolation level, contention virtually disappeared, even with thousands of workers. However, when running more than ~8000 workflows per second, we saw a new bottleneck: high CPU usage. This came from two seemingly unrelated places: the dequeue query itself and Postgres auto-vacuum. We found both sources shared the same root cause: inefficient indexes.
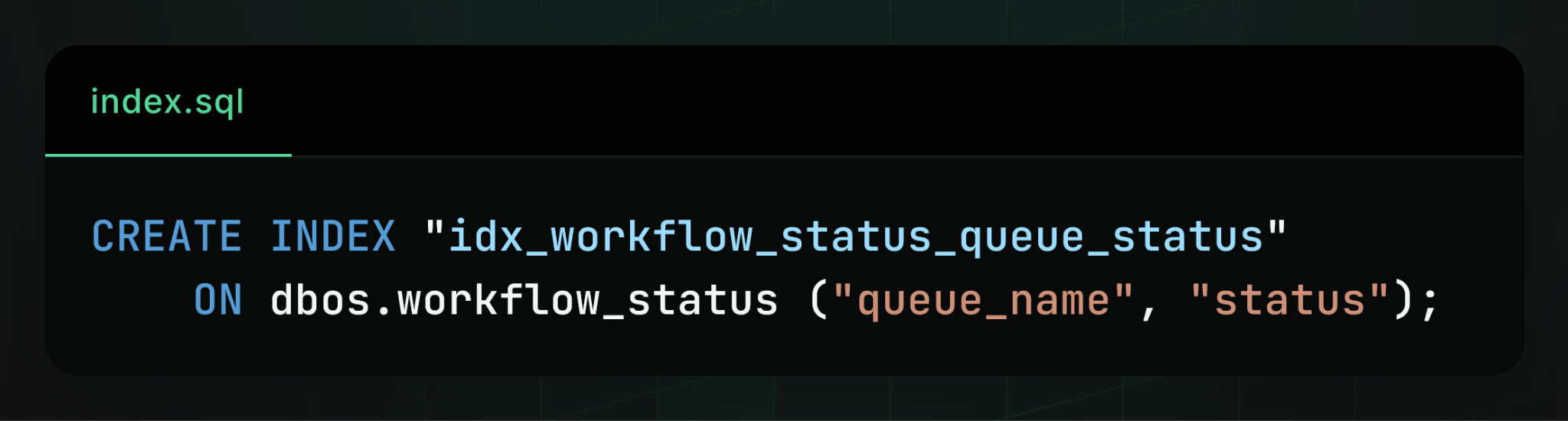
The workflow status table had several secondary indexes on it to speed up queries. One index was designed specifically for the dequeue query, indexing queue_name and status so Postgres could rapidly find all ENQUEUED workflows for a given queue:
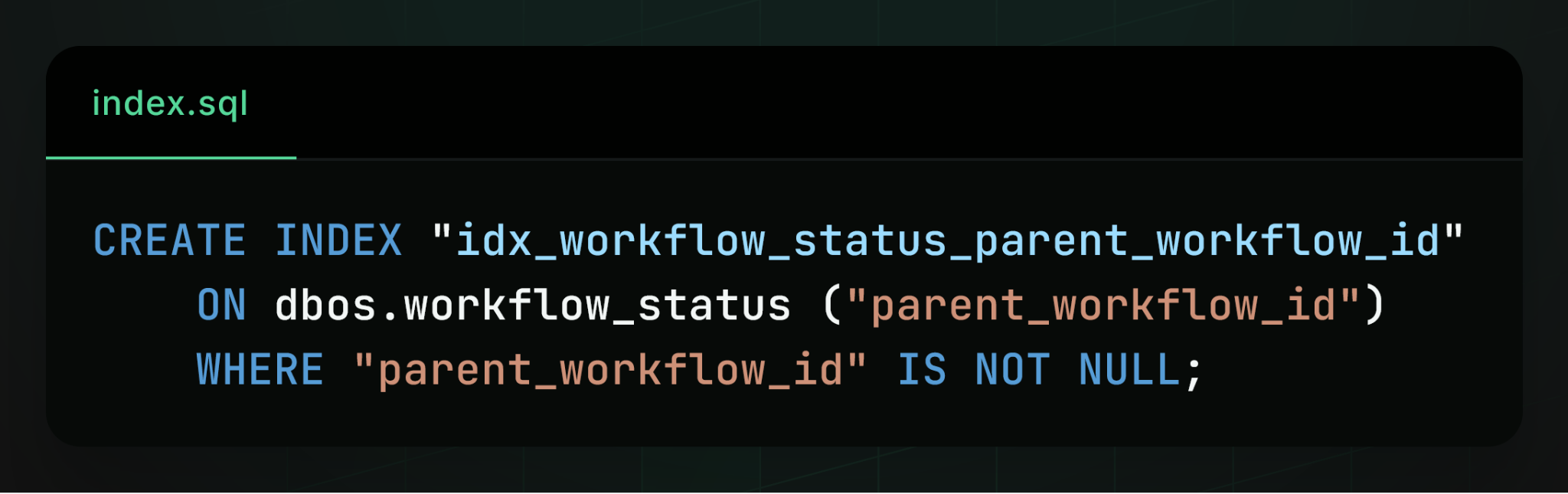
Other indexes existed primarily for observability, for example, an index on parent workflow ID to enable efficient querying of workflow hierarchies:
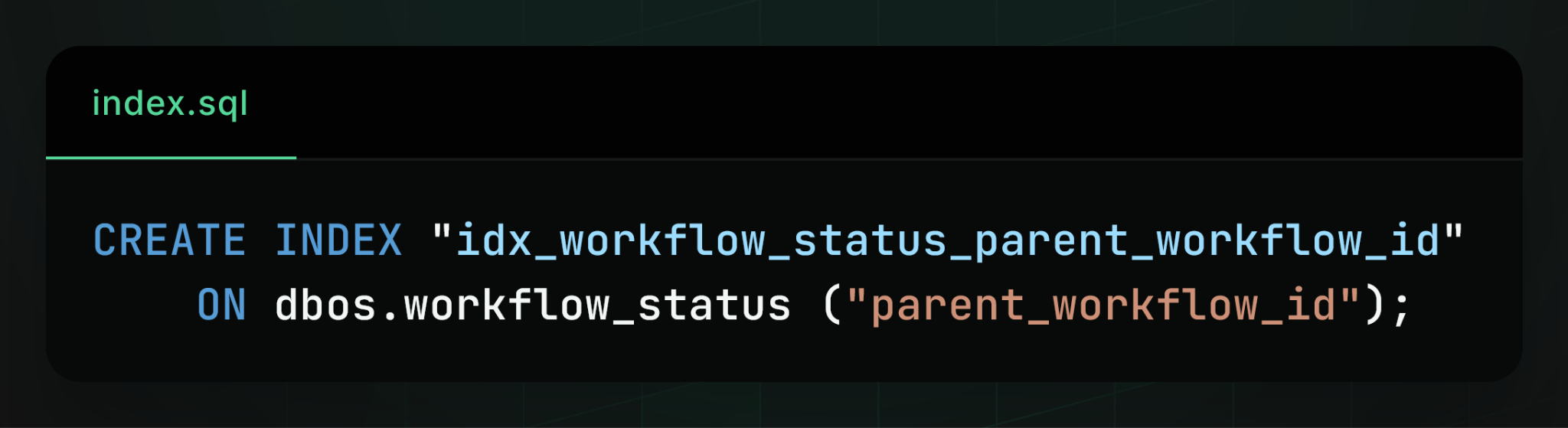
At scale, these indexes were inefficient.
The dequeue index helps find all enqueued workflows, but doesn't return them in any particular order. As a result, when Postgres runs the dequeue query, it has to sort the returned workflows by timestamp to find the oldest enqueued workflows, increasing the query’s CPU usage.
Meanwhile, maintaining many indexes is costly. Every workflow status update (enqueue, dequeue, completion) requires updating every index. Moreover, after indexes are updated, Postgres autovacuum has to clean up outdated index entries. At high throughput, index maintenance and vacuuming consume a substantial fraction of database CPU.
The solution is to make indexes more selective.
First, we updated the main dequeue index so it not only returns all enqueued workflows for a particular queue name but also sorts them by priority and timestamp. Moreover, we converted it into a partial index that’s only maintained when workflow status is ENQUEUED.
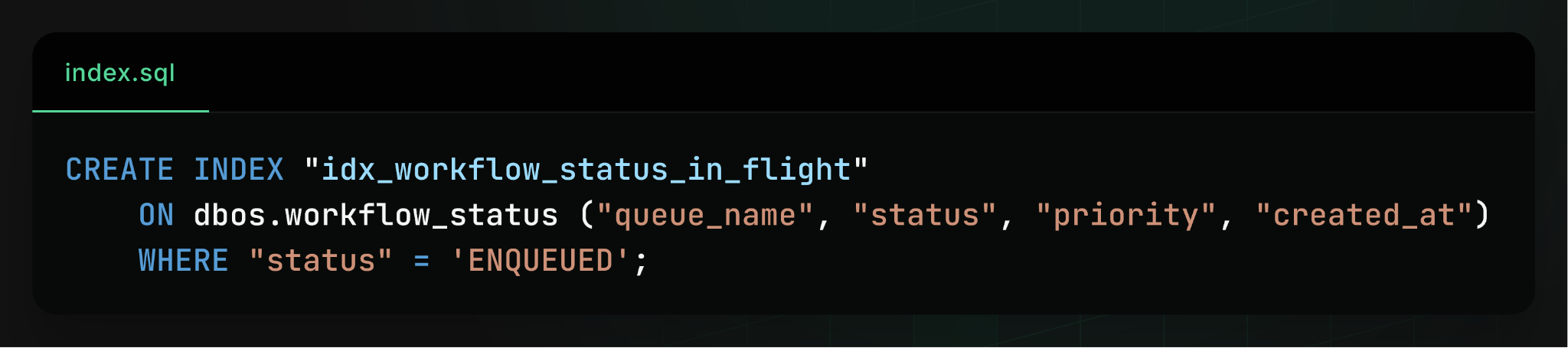
This improves performance for two reasons. First, the dequeue query no longer needs an expensive sort step. Second, when the workflow is dequeued, Postgres can simply delete its index entry instead of maintaining it for the rest of the workflow’s lifetime, reducing maintenance and auto-vacuum cost.
We applied the same principle to most observability indexes. For example, the index on parent workflow ID is only maintained for workflows that actually have a parent:
Combined, these optimizations cut CPU usage dramatically, allowing queues to scale to over 30K workflows per second, or 80B per month.
Learn More
If you like building scalable, reliable systems, we’d love to hear from you. At DBOS, our goal is to make Postgres-backed durable execution as simple and performant as possible. Check it out:
- Quickstart: https://docs.dbos.dev/quickstart
- GitHub: https://github.com/dbos-inc
- Discord community: https://discord.gg/eMUHrvbu67