







Event-driven Programming is Usually a Poor Architecture
Introduction
There has been a lot of discussion about when to use an event-driven programming model and when to use a workflow architecture. Much of this discussion has stemmed from the increase in agentic AI applications. AI agents routinely execute long-running, multi-step processes involving tool calls, external APIs, and human-in-the-loop. They are inherently stateful and failure-prone, which makes coordination and recovery first-order concerns.
In this paper we discuss this tradeoff using Dijkstra's famous CACM letter [1] about GOTO programming for guidance. We begin in Section 2 by presenting a motivating example, which we then show how to solve using both paradigms. Then we continue in Section 3 with a classification system to evaluate the two architectures. Lastly, in Section 4 we bring Dijkstra's comments to bear on our classification system.
Motivating Example
In Figure 1, we show a simplistic, hypothetical B2B ecommerce site - a popular target for agentic AI. There are four modules in the site. When an order for an item arrives, the system first checks its inventory to see if the item is in stock. If so, it continues by deciding if it wants to do business with the prospective customer. This could entail accessing an AI model to evaluate the buyer’s credit rating and order history. If this appears to be a good customer, then the next module accepts payment for the item while the fourth module does fulfillment (shipping). In summary, there are four modules, and the arrows indicate the workflow that must be orchestrated by an underlying workflow engine.
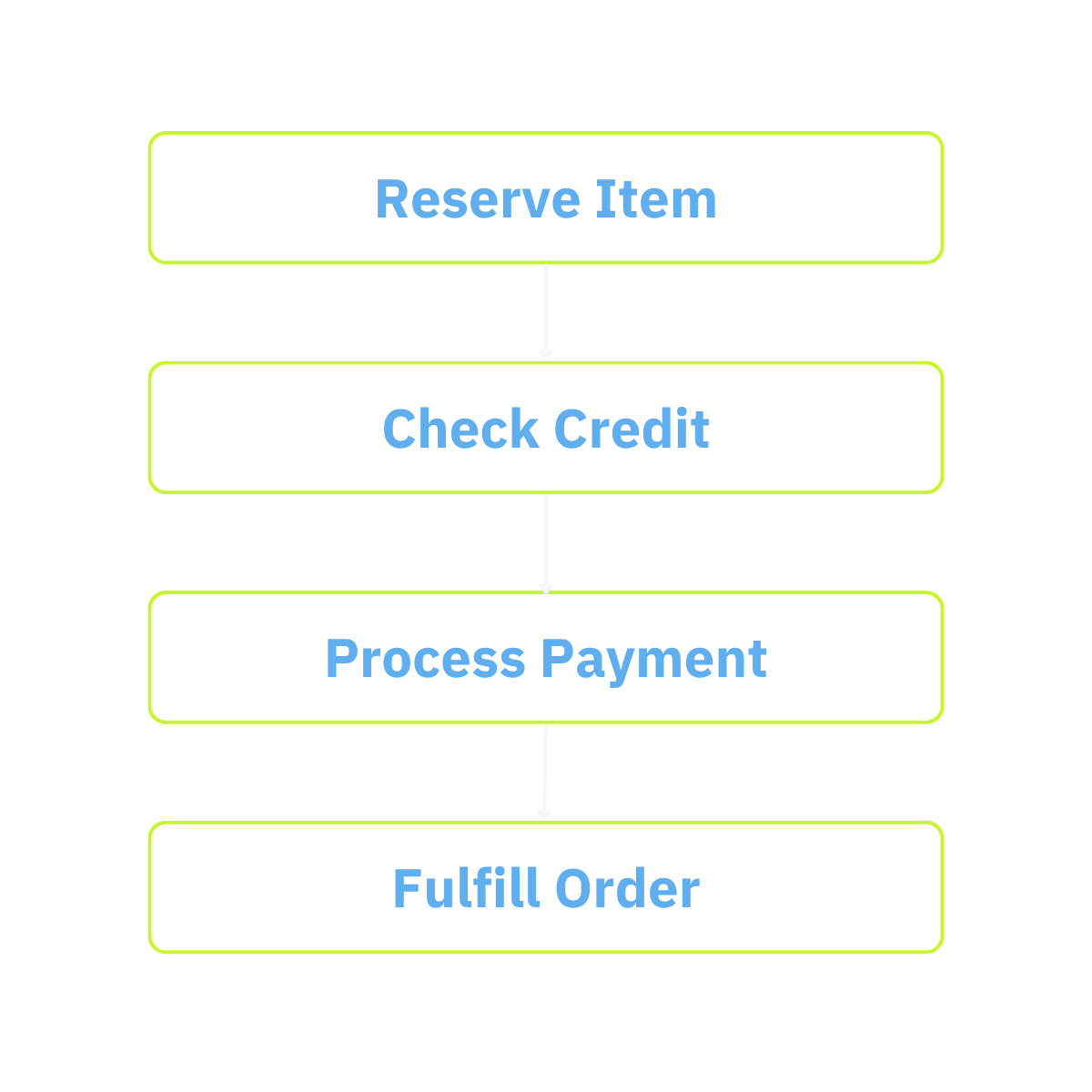
On the other hand, one could also use an event-driven architecture to process orders. In this architecture, shown in Figure 2, there are the same modules, shown as event handlers, one for each workflow step above. These are interconnected by a message bus. This bus could use a pub/sub protocol or some other routing mechanism. Each of the four event handlers would be awakened when an appropriate message was received and then would put a message back on the bus to be received by "the next in line."
The message bus would be responsible for supporting the routing conditions and making sure all messages get processed correctly. In our example case, the message bus would effectively implement the sequencing of modules.
It is clear that either architecture can be made to work, so we turn now to a classification system to discuss the choice in a principled manner.
Classification System
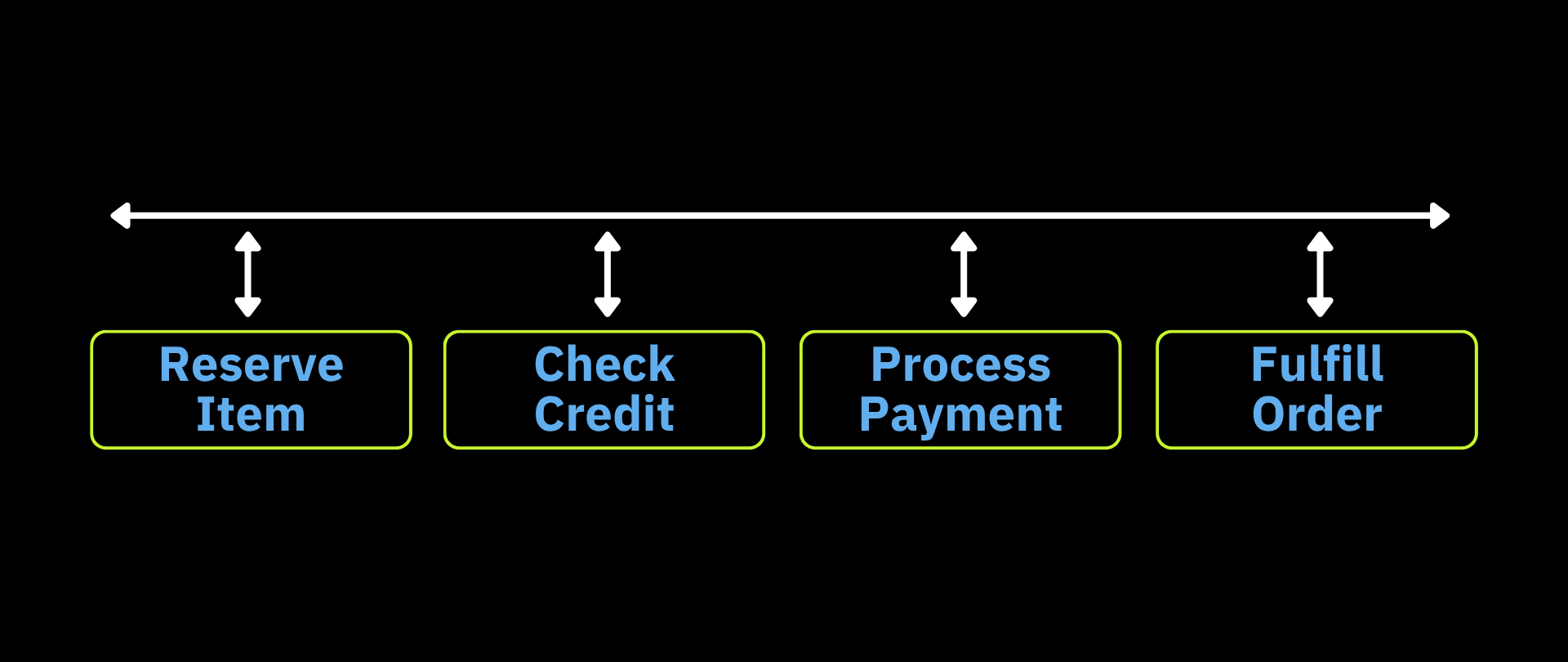
Since single-step applications would not expect to use either paradigm, we consider only multi-step ones. Figure 3 shows two axes along which we will classify such applications. The vertical axis indicates whether the steps are independent; in other words, whether any step depends on the results of another step (meaning the steps can run in parallel, as opposed to sequentially). In our example, the steps are dependent because an item cannot be shipped if it is not in stock. Also, one cannot take money from a customer if the vendor does not want to do business with them.
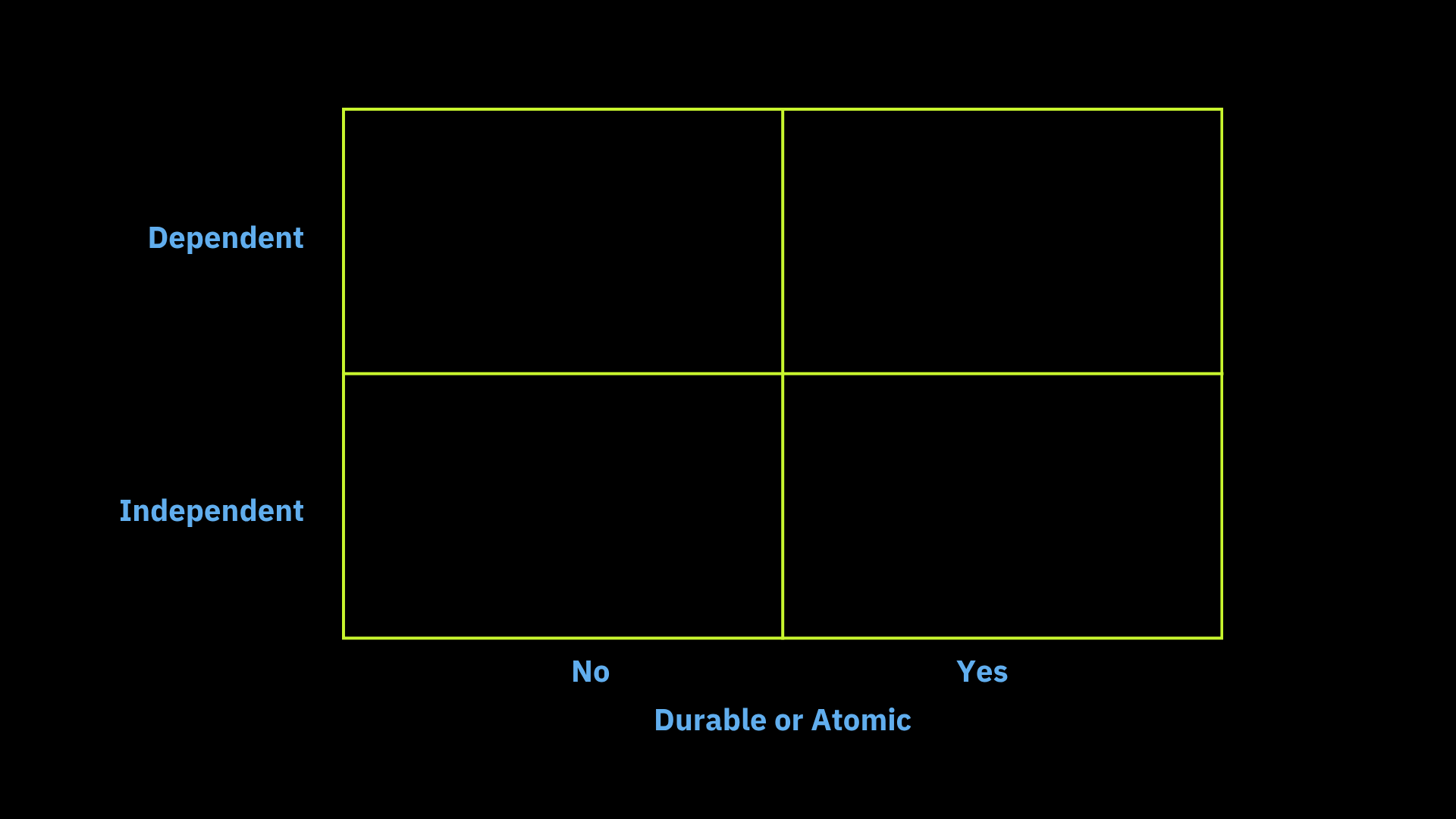
The horizontal axis classifies multi-step applications as requiring either durability or atomicity. Atomicity is required if the application has only two permissible final outcomes: Either it fully and successfully completes, or it must look like it never started. This all-or-nothing behavior is used to guarantee that the state of an accompanying database or databases is always left in a consistent state. In our application, one wants to ensure that the customer only pays for the ordered item if it is shipped. Otherwise, the reserved item must be returned to inventory. A less demanding condition is durability. In this case, if the application fails partway, either because of a software or hardware error, then the application can pick up where it left off when the error is resolved. This saves resources if the application is long-running because previously completely steps do not have to be reprocessed. It also, guarantees that an item will not be reserved twice or paid for twice.
Dijkstra’s Letter
In 1968, Dijkstra published his famous letter in CACM [1] decrying the excessive use of the “GOTO” construct. Although others have questioned the reasoning in his letter [2], there is near universal agreement that “blind jumps” (GOTOs) in a program generate the following issues:
- Difficulty in understanding the program. A lot of GOTOs tend to produce a messy code base (spaghetti code).
- It is hard to deal with run time errors. Often, the problem originates far away from the current module, and tracking down the issue is difficult.
- Initial Debugging. If an error occurs, it is often difficult to figure out what happened.
It is now 58 years since the Dijkstra letter, but all programmers and architects should heed his advice. In today's world, we use it as a framework to discuss event-driven programming versus workflow systems using the classification system above.
4.1 Understandability
If we look at Figure 1 it is clear what the flow of control is. Also clear is the business logic being performed. On the other hand, in Figure 2, the flow of control and the business logic is obscured. Obviously, Figure 2 is harder to understand than Figure 1. In this dimension, one should favor a workflow architecture.
4.2 Errors
Under normal circumstances, the modules finish correctly, and control moves to the next module. In this case, both architectures should work well; however, errors are a different matter entirely.
The complexity of this application comes from required error logic and “oops” logic. Each step in the workflow can fail. The desired item may be out of stock, the credit card may be declined, and the customer may give a bad address for fulfillment. The error logic for each step must be included in the application. For example, a bad address for fulfillment may require the whole workflow to be unwound.
Moreover, a resilient application also requires "oops" logic to handle unexpected failures. If the seller’s site crashes, then they have to pick up the pieces and make sure there are no partially complete sales. The site may become overloaded and response time may become intolerable. In this case the buyer may go away, leaving an incomplete transaction.
In our experience, the forward logic is 10% of the application while the error and "oops" logic are 90%. Clearly, handling failures requires either architecture to support crash recovery and failover. Hence, we discuss the error logic.
The corrective action for an error may be to send a message to a different module, for example to try another warehouse if there is no inventory in the first one. This requires either architecture to add a new action and appropriate plumbing. However, it is entirely possible that the corrective action is to abort the workflow. In other words, back out the entire path of actions, either by compensation or by undoing each action in the path of execution.
This is natural in a workflow world, where one conceptually wants to make a given workflow instance atomic. In other words, the workflow instance either completes or looks like it never happened. In an event driven architecture, this is difficult to code, because each event handler is independent of the others, and it is difficult to perform global operations. The net-net is that for 90% of the application (the error path), a workflow architecture is superior.
4.3 Debugging
In Figure 2, note that all of the event handlers are designed to be independent of each other, taking a message off the bus, processing it and putting a new message back on the bus.
It is straightforward to debug the individual handlers since there is sequential flow of control and localized execution. However, in the words of John Ousterhout, “what happens if you fail due to the actions of somebody you know nothing about?" This could happen if one or more values in your input message are wrong or missing. The mistake is somewhere else, and debugging must somehow assemble the sequential logic that led to the current state. This is obviously a challenge in an event-driven architecture. If every handler is writing a log, one must trek through multiple logs looking for the error.
On the other hand, durable workflow systems give every workflow instance an identifier and automatically write a single log with records containing this identifier. Therefore, it is straightforward to move backward through the log to find the error. As a result, I claim that debugging is easier with a workflow architecture. As a result, we are led to conclude that a workflow architecture has obvious advantages in three of the four boxes as noted in Figure 4. In the lower left corner, the disadvantages of an event-based architecture are muted because the steps are truly independent, without atomicity or durability constraints.
Conclusions
In independent, non-durable, non-atomic, applications, an event-based architecture will work well. There are no dependencies to deal with and understandability is not compromised. Similarly, there are no dependencies introduced by a desire for atomicity or durability. In all other cases, a workflow architecture is clearly preferred. This is also why many recent AI frameworks are converging on a workflow-style model and supporting durable execution.

Many, many workflows desire durability to easily pick up the pieces after a failure and/or to avoid redoing already processed steps. In addition, whenever a multi-step application performs updates, as our e-commerce application does, then it is highly likely that one would value atomicity. As a result, we claim the vast majority of applications are not in the lower left-hand corner of our table, and an application designer should almost certainly use a durable workflow architecture.
References
[1] Dijkstra, Edgar, “Go To Statement Considered Harmful,” CACM, March 1968.
[2] Rubin, Frank, ““ Go To Considered Harmful” Considered Harmful,” CACM May 1987.