






Say you’re building a workflow for monthly usage-based billing of customers. The workflow looks up the customer’s usage, generates an invoice, bills the customer with the invoice, then sends the customer a receipt. You annotate workflows and steps in your code like this:
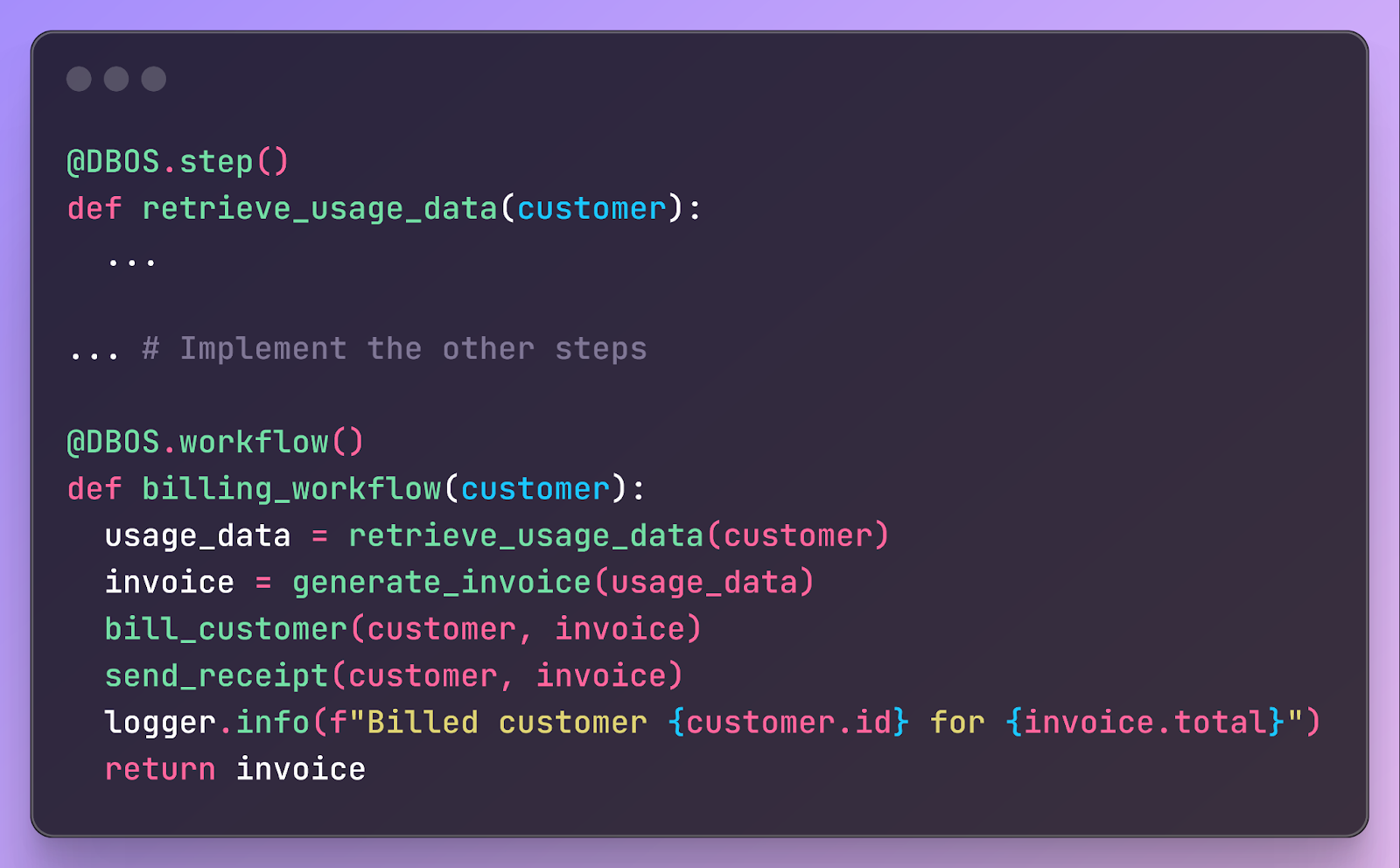
The annotations checkpoint workflows and steps into your database, such as Postgres, like this:
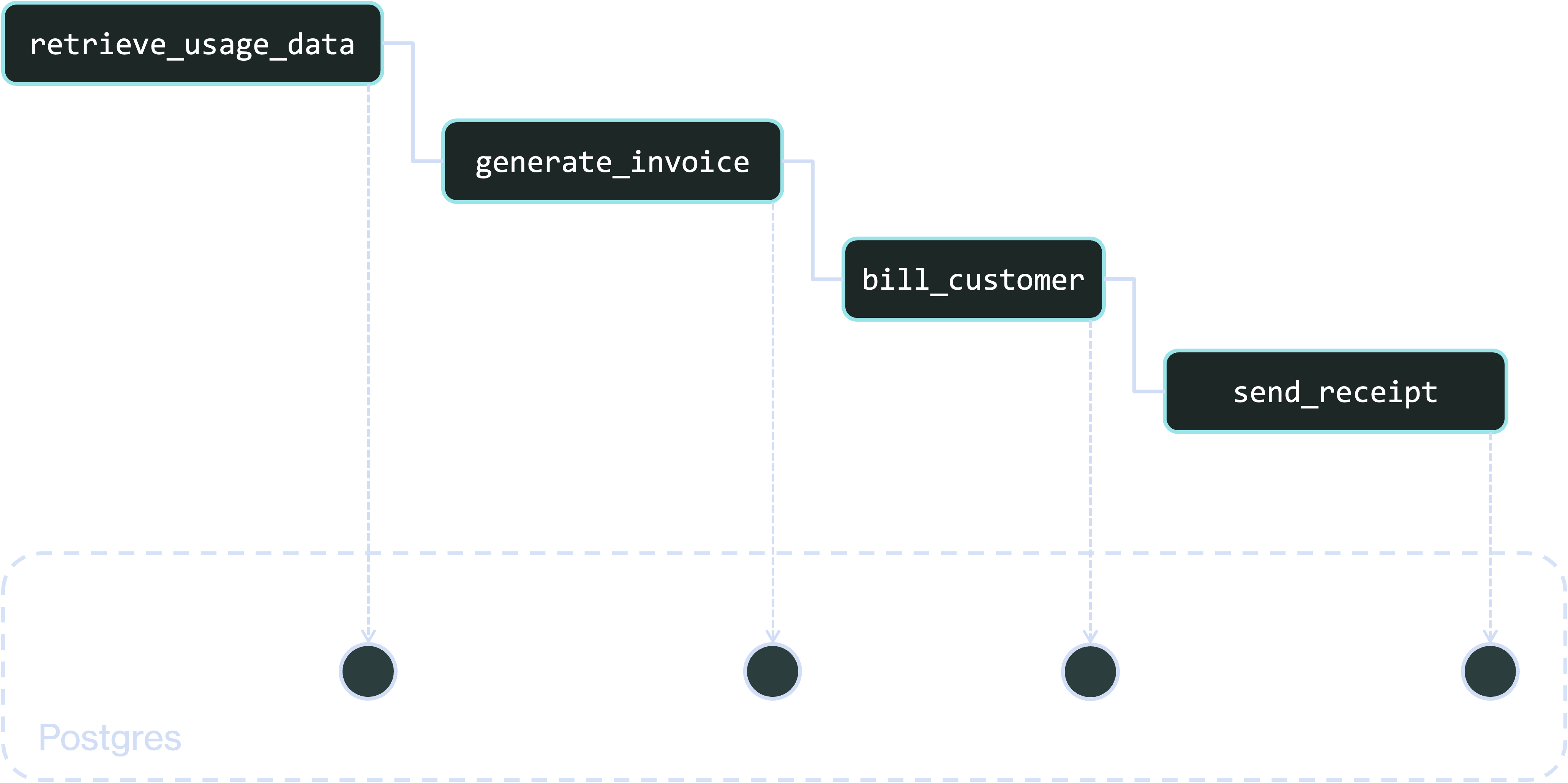
Essentially, this represents your business processes as rows in database tables. That’s remarkably powerful because database rows are easy to query and manipulate. If you have thousands of workflows running across fleets of servers, it’s difficult to determine from logs and telemetry what each is doing. If there’s a disruption – a software bug or a failure in an downstream service – it’s difficult to figure out which workflows were affected and how to recover. But if those workflows are backed by database rows, then those operations can be reduced to SQL queries.
In this post, we’ll examine this idea – how Postgres-backed workflows simplify operating complex systems. First, we’ll dive deep into how the Postgres representation works under the hood. Then we’ll show how it enables recovery from complex failures by performing database operations over workflow state.
Storing Workflow Execution in Postgres
Representing workflows in Postgres is powerful because it can completely encapsulate the state of the workflow. It enables reconstruction, at the granularity of individual steps, of what the workflow was doing at any moment in time.
Let’s take a look at how this works. Workflow state is represented in two main tables. The first, the workflow_status table, describes the state of the workflow as a whole. It has a row for each workflow execution, containing its unique identifier, the name of the workflow function, the current status of the workflow, and the workflow’s serialized inputs and (if available) outcome.

The second table, operation_outputs, describes the state of the workflow’s steps. When a step completes, it writes a row to this table, containing the workflow’s ID, the step’s unique ID within the workflow, the step’s name and its outcome (output or error):

You can think of these tables as checkpointing a program in Postgres. First, checkpoint the workflow itself in the workflow_status table, then checkpoint the outcome of each individual step in the operation outputs_table, then finally checkpoint the result of the workflow in the workflow_status table.
You can use these checkpoints to reconstruct, at the granularity of individual steps, what the workflow was doing at any moment in time. To do this, re-execute the workflow function using its checkpointed inputs. Whenever you encounter a step, instead of executing the step, return its checkpointed output. This faithfully reconstructs the workflow’s state as long as the workflow is deterministic – if called multiple times with the same inputs, it should invoke the same steps with the same inputs in the same order. Non-deterministic operations must be placed in steps so their outcomes are checkpointed.
Handling Failures With Postgres-backed Workflows
The power of Postgres-backed workflows is that they greatly simplify operations by representing business processes as rows in Postgres tables, which are easy to query and manipulate.
This is clearest when recovering from a failure in production, especially one that might affect thousands of workflows in unpredictable ways. Let’s say that the billing service experiences an outage early in the morning and the billing workflows for many customers fail. Without a record of the workflows, there’s no easy way to tell which customers were affected by the outage, so you need a complex manual recovery process to figure out which customers to bill. But with durability, the state of the failed billing workflows is saved in Postgres:
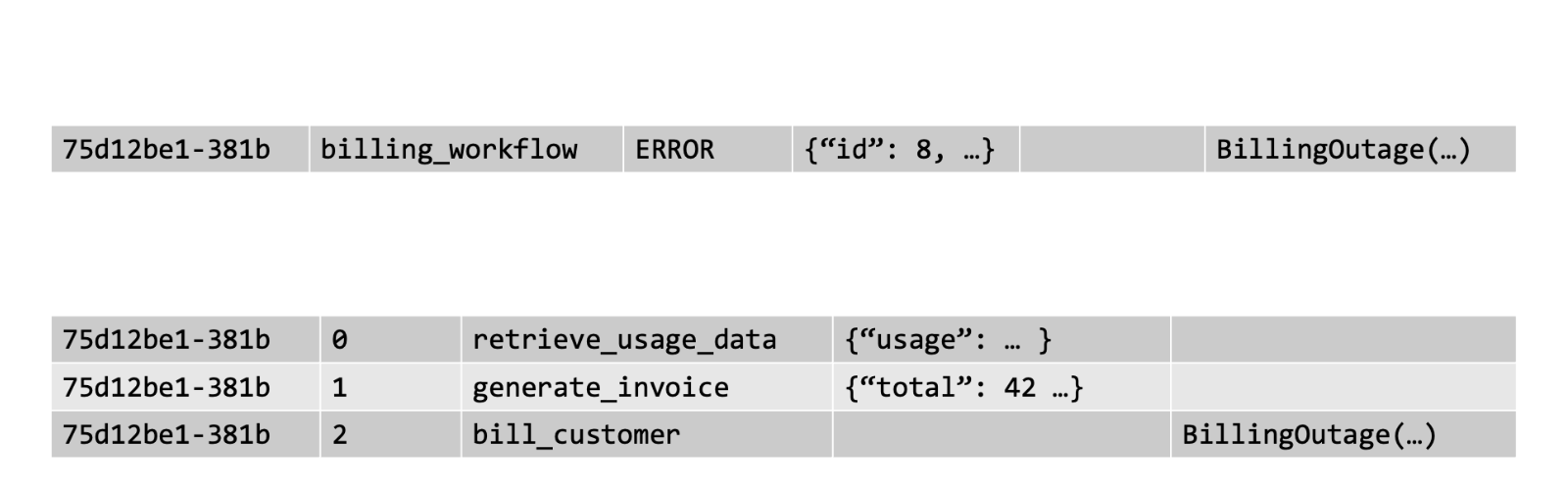
Using this information, we know exactly which customers were affected by the outage. We can then go a step further and programmatically recover each customer. To do this, we find all customer billing workflows that failed due to the outage and restart them from the billing step. All this requires is a short script:
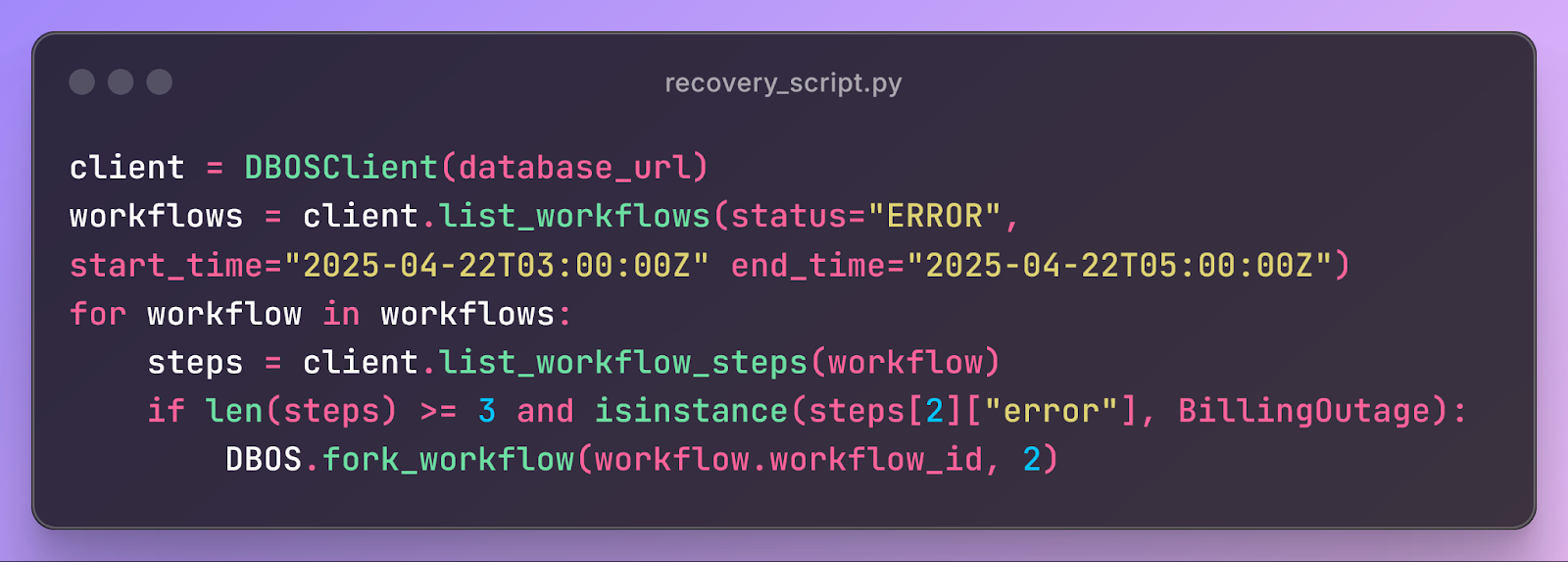
Each line in the script corresponds to a SQL query against Postgres. First, use list_workflows to list all workflows that failed during the billing system outage:

Then, for each workflow, use list_workflow_steps to list its steps and check if the third step (the billing step) failed due to the billing service outage:

For all workflows that failed due to the outage, use fork_workflow to restart them from the billing step. This creates a new workflow with the same inputs and checkpoints up to the billing step, but a new workflow ID and PENDING status:

Using the information stored in these rows, the billing workflows for all affected customers can resume from the billing step. Assuming the outage has been resolved, these restarted workflows will successfully bill customers using the checkpointed invoices. Thus, this script can resolve a serious production incident in ~6 lines of code.
This pattern is extremely powerful. If you can represent your business processes as rows in a database table, you can more easily recover them from complex failures affecting thousands or millions of workflows – not only outages in downstream services, but also software bugs in business logic or failures in dependencies. It’s another form of observability, but goes beyond observability to enable you to manage your application state.
Get Started with Durable Workflow Orchestration
We built the open-source DBOS Transact library (Python, TypeScript, Go, Java) to make Postgres-backed workflows as easy as possible to build and operate. Using DBOS and Postgres, you can build software that is reliable and durable by default.
To try it out, check out the DBOS Transact quickstart.