








Everyone knows serious programs must make data durable. You persist data on disk or in a database so it doesn’t disappear the second your program crashes or your server is restarted. But we also take it for granted that programs themselves aren’t durable. When you restart your server, your data might be safe in the database, but any programs you were running are gone, and if you want them back, you have to restart them yourself.
Now, restarting your programs might be fine if they’re short-lived and stateless, but what if they’re long-lived or stateful? Let’s say your server handles hotel reservations, and it's halfway through processing a reservation when it’s restarted. What happens to the reservation? Alternatively, what if your server is indexing a batch of 10K documents for RAG, but is restarted after only finishing 4K? What happens to the other 6K documents?
Durable execution helps solve these problems. At a high level, the idea is to persist the execution state of your program as it’s running. That way, if your program is ever crashed, interrupted, or restarted, it can automatically recover to where it left off. Currently, durable execution is implemented “as a service” by external orchestrators that manage your program’s control flow. In this post, we’ll show how to implement durable execution in an open-source library you can add to any program.
Heavyweight Durable Execution - External Workflow Orchestration
The first wave of durable execution systems, including AWS Step Functions and Temporal, are based around external orchestration. The idea is that you write your durably executed program as a workflow of steps. Each step is just an ordinary function–it takes in an input, does some work, and returns an output. The workflow wires all the steps together and is durably executed, so if the program is interrupted, it can be resumed from the last completed step. For example, a workflow for hotel reservations might look like this:

Architecturally, externally orchestrated systems are made up of an orchestrator and a bunch of workers. The orchestrator runs the actual workflow code, dispatching steps to the workers through queues. The workers execute the steps, then return their output to the orchestrator. The orchestrator persists that output to a database, then dispatches the next step. Typically, the orchestrator and workers run on separate servers and communicate via message-passing, hence the name external orchestration.
Because the orchestrator persists the output of every step, this setup is. If a worker crashes, that’s okay, the orchestrator can re-dispatch its steps to some other worker. If the orchestrator crashes, that’s also okay, it can lookup all in-progress workflows in its persistent store and resume them from their last completed steps.

While external orchestration works, it’s not easy to use. External orchestration is heavyweight, which complicates the way you develop, deploy, and maintain programs. To run even the simplest program, you have to start an orchestrator server and a worker server, load your workflows and steps to those servers, and then submit a request to the orchestrator to start a new workflow. This adds friction to every step of developing, testing, and debugging your applications. In some sense, external orchestration turns individual applications into distributed microservices, with all the complexity that implies.
Lightweight Durable Execution
If external orchestration is too heavyweight, how do you make durable execution lightweight? We believe the key is to implement durable execution in a library that you include in your program. That way, you can write your workflows and steps as ordinary functions and run them in an ordinary process, and the library takes care of persisting their execution state and resuming them after an interruption.

Based on this idea, we built and recently released DBOS Transact, a fully open-source library for durable execution. We built it to make durable execution as simple as possible to use. Here’s what a “Hello, world” program looks like:
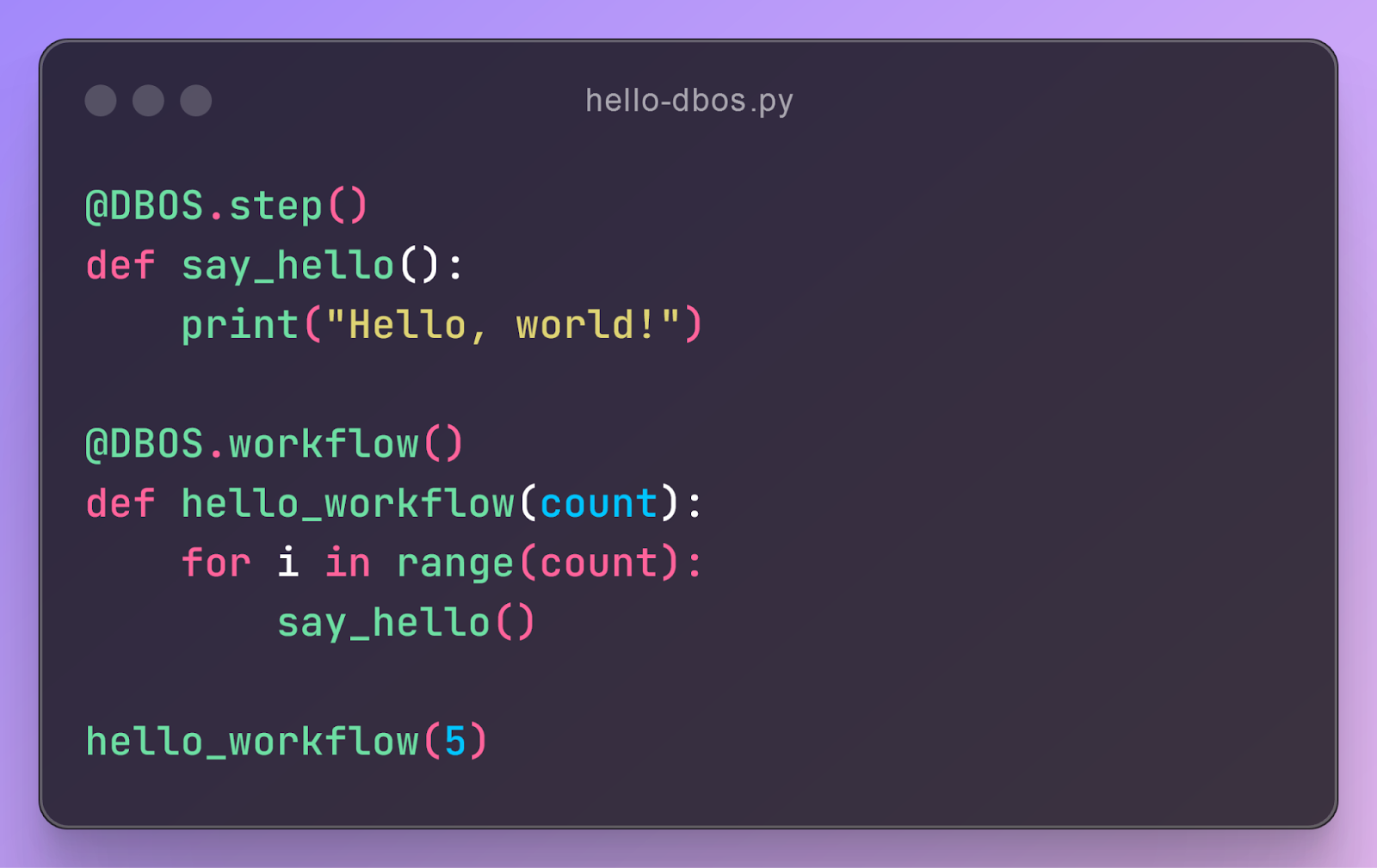
This is durably executed! If you crash it after saying “Hello” twice, upon restart it will say “Hello” three more times. But it’s also an ordinary Python program–you start it with python3 hello-dbos.py and it runs in a normal Python process.
So how does this work? The key is in those decorators, DBOS.workflow() and DBOS.step(). They wrap your functions with the code that durably executes them. At a high level, they persist your program’s execution state–which workflows are currently executing and which steps they’ve completed–in a Postgres database.
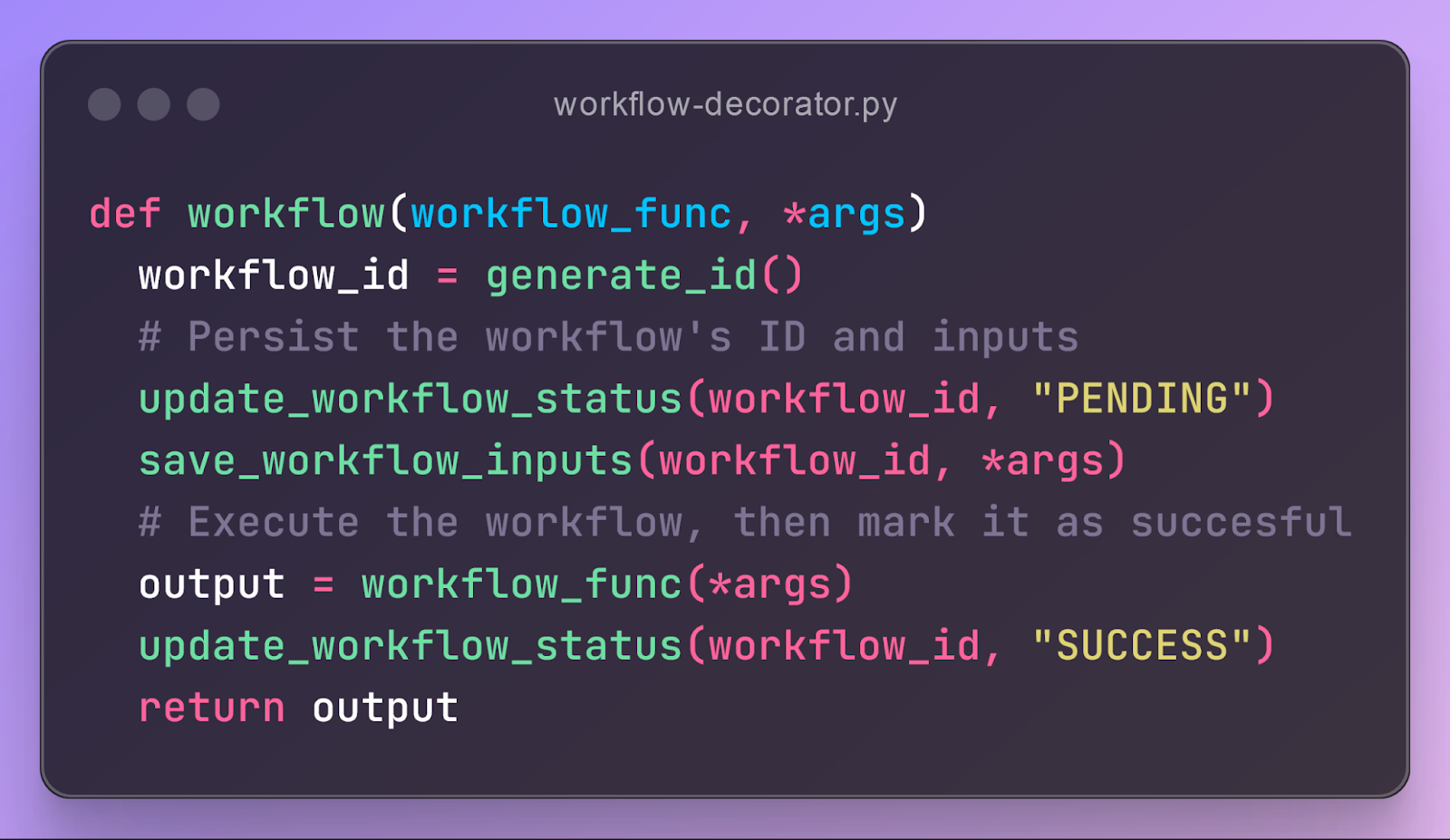
When you call hello_workflow(5), before the actual hello_workflow function starts, the workflow decorator kicks into action. It generates a unique ID for this workflow instance and persists it to a Postgres workflow_status table with a PENDING status. It also persists the workflow’s inputs to a workflow_inputs table. Once both status and inputs are safely persisted, it starts the hello_workflow function. At a high-level, here’s what the code for the workflow decorator looks like:
hello_workflow executes as an ordinary Python function. However, each time it calls say_hello, that function’s step decorator executes. The decorator waits until the step completes, then persists its output to a Postgres operation_outputs table before returning it to the workflow. This happens five times, one for each loop iteration, so eventually five say_hello records are persisted. At a high level, here’s what the code for the step decorator looks like:
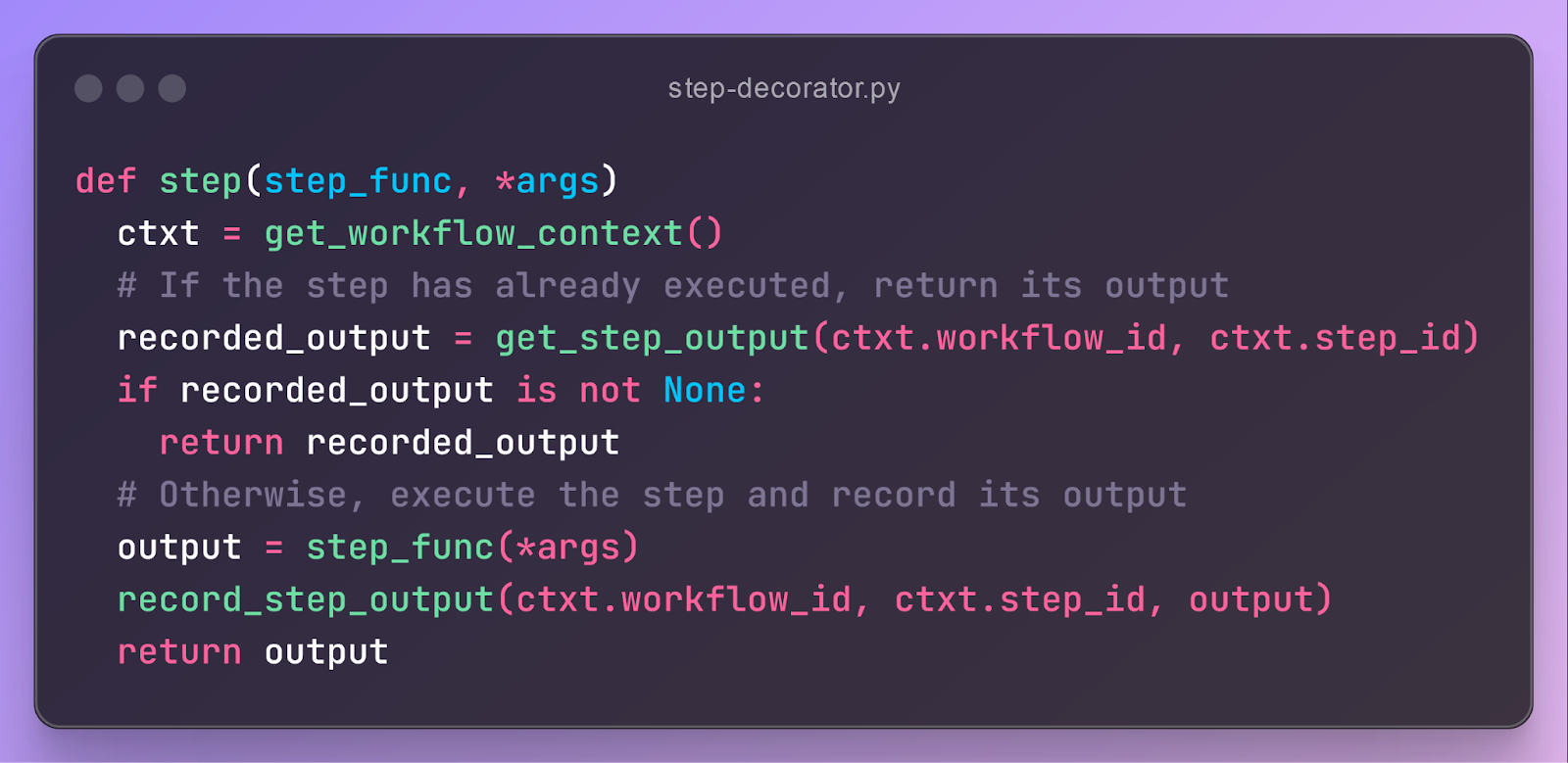
Finally, after the workflow completes, the workflow decorator updates its status in the workflow_status table to SUCCESS.
So what happens if your program crashes midway through execution? Because the decorators are storing all this information in Postgres, upon restart the DBOS library can resume all your workflows from the last completed step. Here’s how that works.
When the DBOS library is initialized on program restart, it launches a background thread that recovers incomplete workflows. This thread queries Postgres to find all workflows that are still in a PENDING state and starts them. Because workflows are just Python functions, the thread can restart a workflow by simply calling the workflow function with its original inputs and ID, retrieved from Postgres. Here’s the high-level code for recovery:
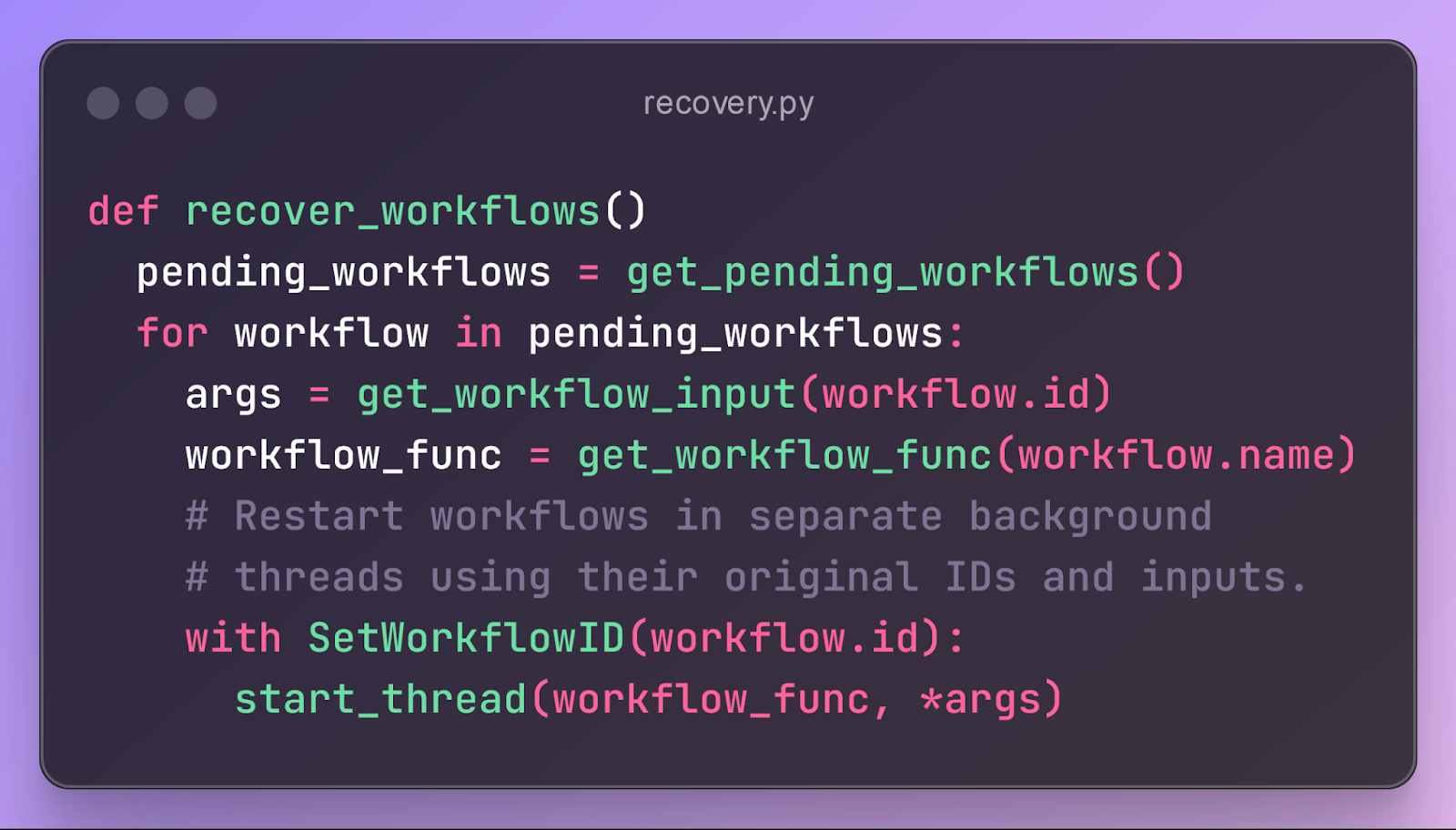
Each time the recovered workflow calls a step, before starting the step, the step decorator checks in Postgres if that step was previously executed. If it finds the step in Postgres, it doesn’t re-execute the step, but instead directly returns its recorded output to the workflow. This continues until, eventually, the workflow reaches the first step whose output isn’t stored in Postgres. It then resumes normal execution from there, running the workflow function and its steps to completion. Thus, an interrupted workflow automatically resumes from the last completed step.
For this model to work, we have to make one assumption: workflow functions must be deterministic. If called multiple times with the same inputs, they should invoke the same steps with the same inputs in the same order. That way, the recovery procedure can use information stored in Postgres to recover each workflow to the exact state it had before it was interrupted. Of course, external orchestrators also require workflows to be deterministic, for similar reasons. In practice, we’ve found it fairly natural to make workflows deterministic, as all you have to do is put all non-deterministic operations, such as database lookups or API calls, in steps (which is easy as any Python function can be a step).
But Wait, There’s More
One big advantage of doing durable execution in a library is that it’s naturally extensible with other features useful for writing reliable, stateful programs, all backed by Postgres and fully integrated with durable workflows. Here are some of the features we find most interesting with a quick sketch of how they work:
- Durable sleep: When you call
DBOS.sleepfrom a workflow it stores its wake-up time in Postgres, then goes to sleep. If the workflow is interrupted and recovers, it looks up its wakeup time in the database and continues sleeping towards it. Thus, you can write “sleep one month” and it will work, even if your program is interrupted or restarted during that month. - Durable messaging: Like durable sleep, but instead of just sleeping, your workflow waits (with a potentially very long durable timeout) for a notification. When another request delivers the notification, it’s written to a Postgres table, which activates a Postgres trigger, which uses Postgres
NOTIFYto wake up the workflow. - Durable queues: A Postgres-backed job queueing system, useful for running many tasks in parallel from a durable workflow. Under the hood, this works (and is durable) because enqueueing is implemented as starting a new workflow asynchronously (with some logic in Postgres to help you control how often and with what concurrency enqueued workflows are started)
- …and more! We’re constantly adding new features to the library–durable execution is an incredibly powerful abstraction, and Postgres is an incredible base to build from.
Try it Out
If you like making systems reliable, we’d love to hear from you. At DBOS, our goal is to make durable workflows as lightweight and easy to work with as possible. Check it out:
- Quickstart: https://docs.dbos.dev/quickstart
- GitHub: https://github.com/dbos-inc
- Discord community: https://discord.gg/eMUHrvbu67