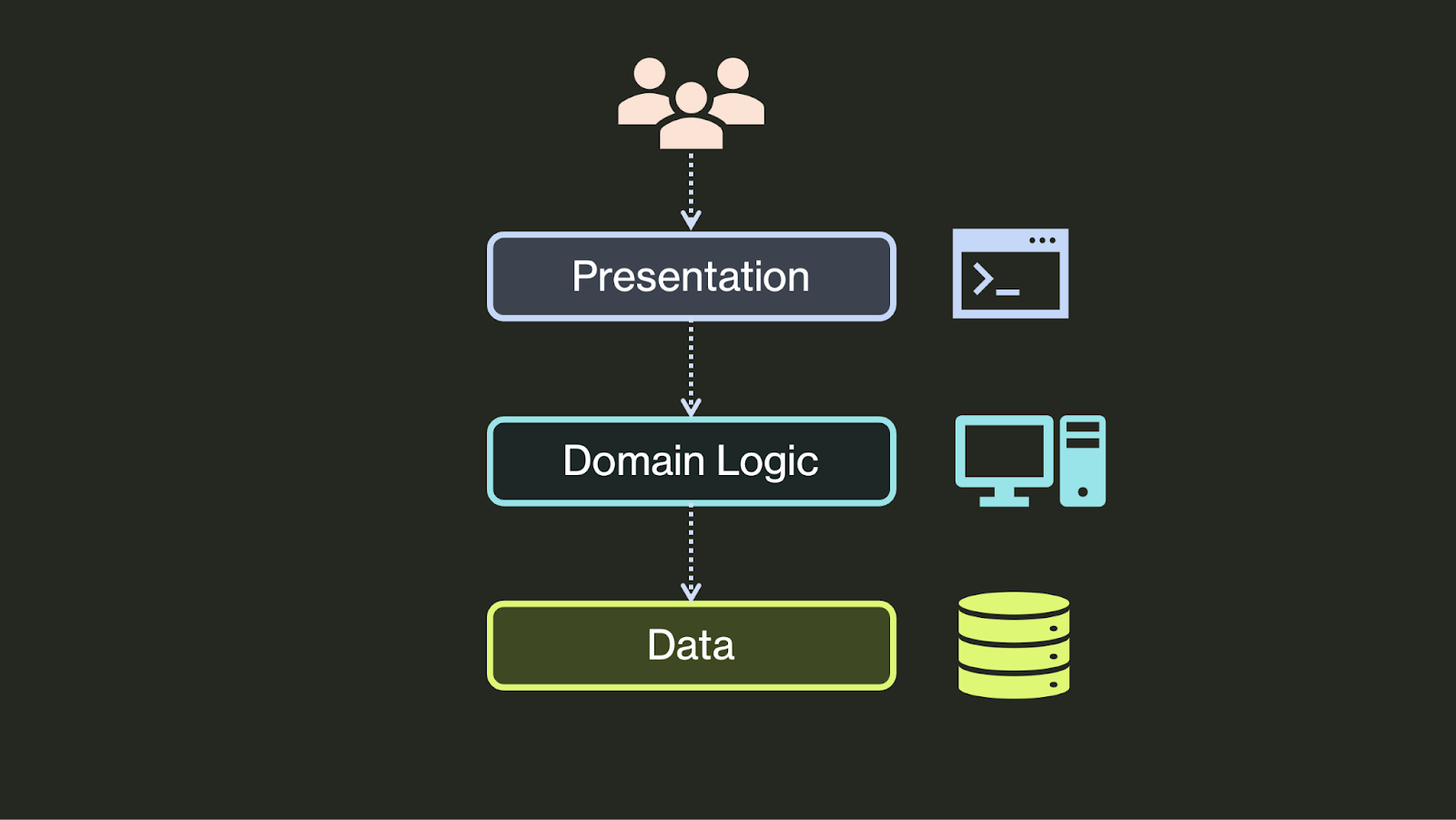
In the beginning (that is, the 90’s), developers created the three-tier application. Per Martin Fowler, these tiers were the data source tier, managing persistent data, the domain tier, implementing the application’s primary business logic, and the presentation tier, handling the interaction between the user and the software. The motivation for this separation is as relevant today as it was then: to improve modularity and allow different components of the system to be developed relatively independently.
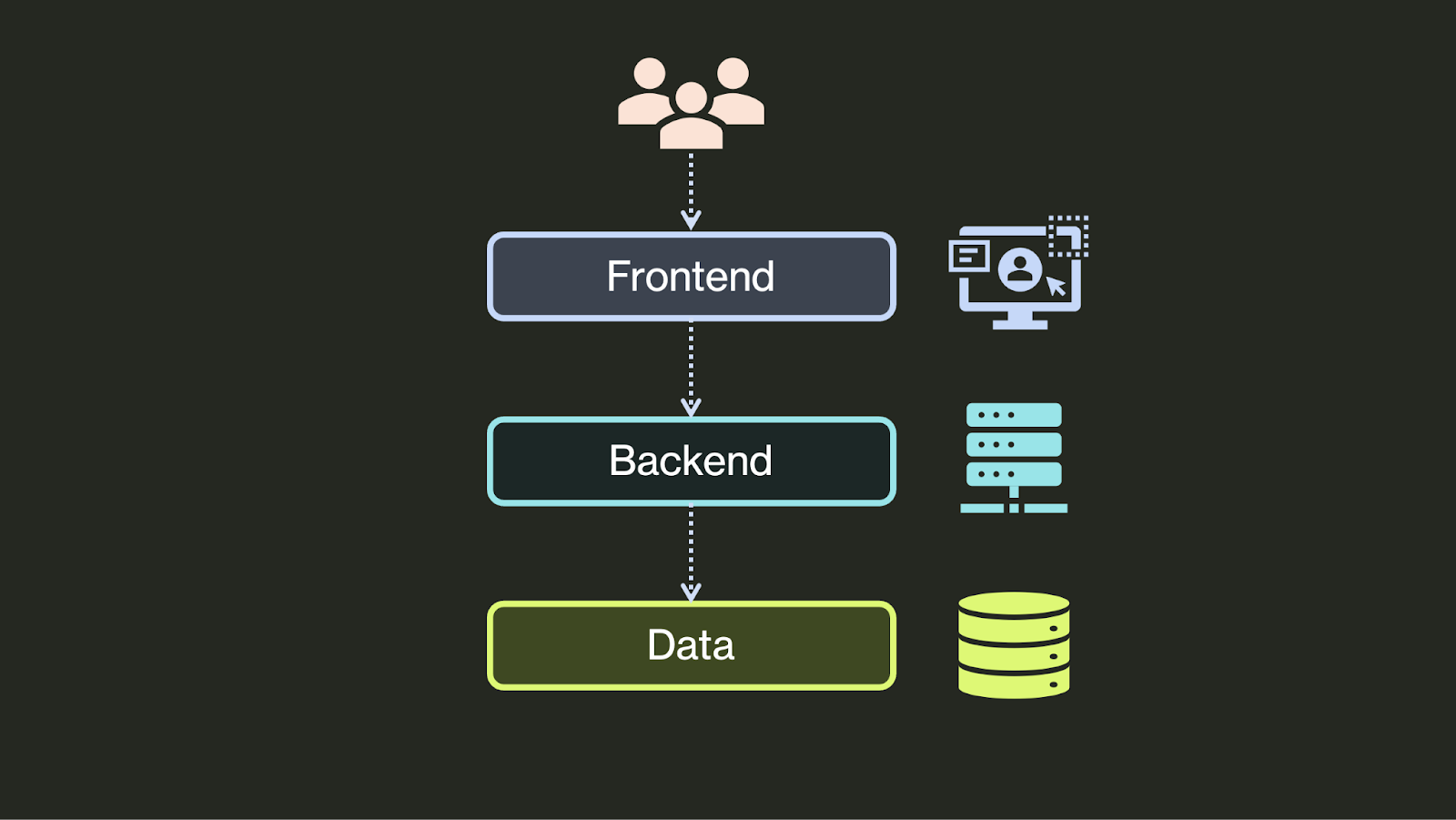
Of course, application architecture has evolved greatly since the 90's. The first big change was in the presentation tier. While most applications once used native clients or the terminal as their interface, they’ve now mostly moved to a web interface. Thus, the presentation tier became the frontend and the domain tier became the backend:
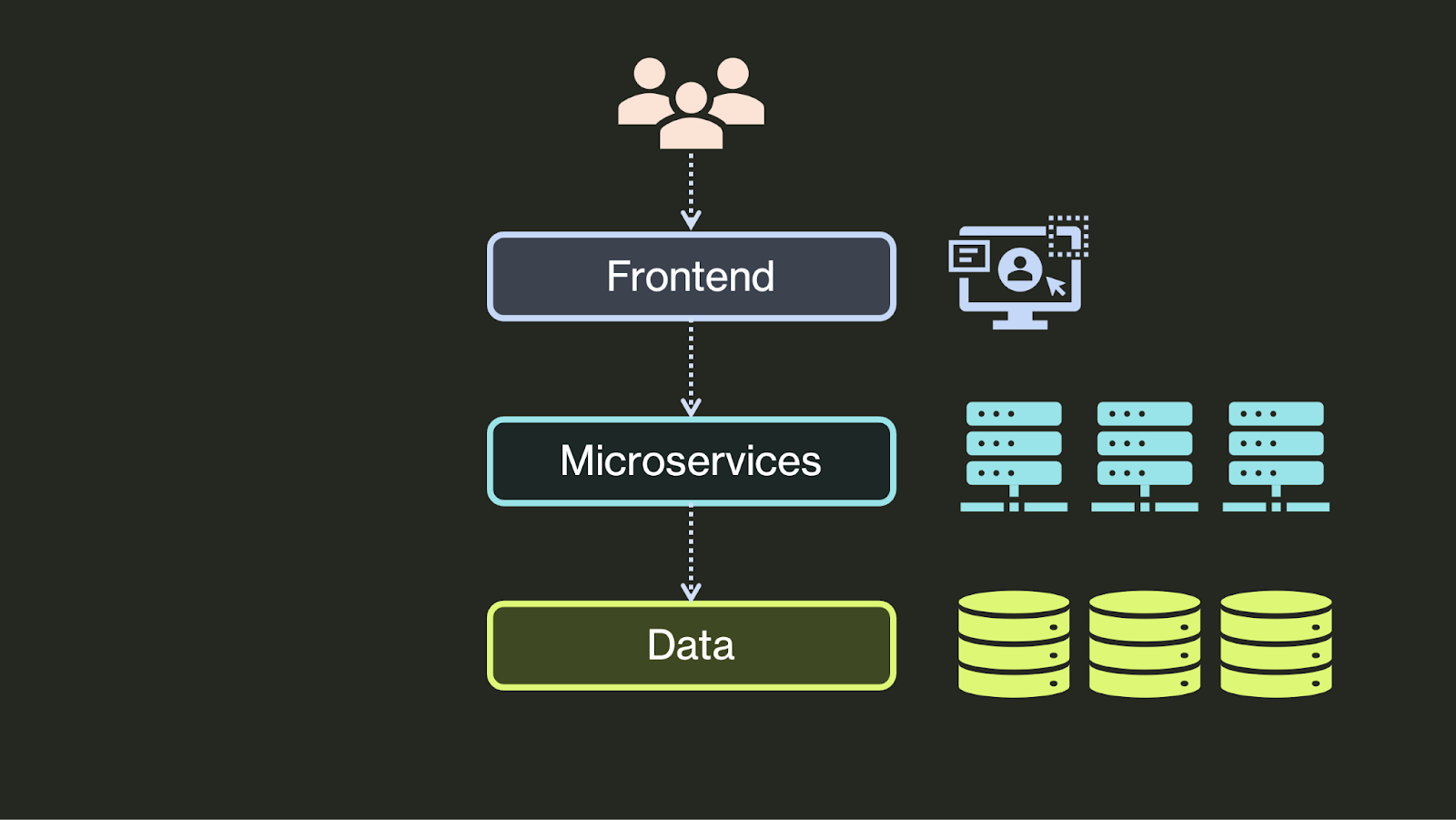
Over the last ~15 years, an even larger shift has occurred in the domain tier/backend. These used to be largely monolithic, implemented in a single software artifact on a single server. However, as both the computational complexity (increasing data volumes and processing demands) and organizational complexity (larger engineering organizations, specialized domain knowledge, need for parallel development) of applications increased, developers began distributing them into many loosely-coupled microservices and even serverless functions. Nowadays, a single application’s backend can consist of many interoperating services:
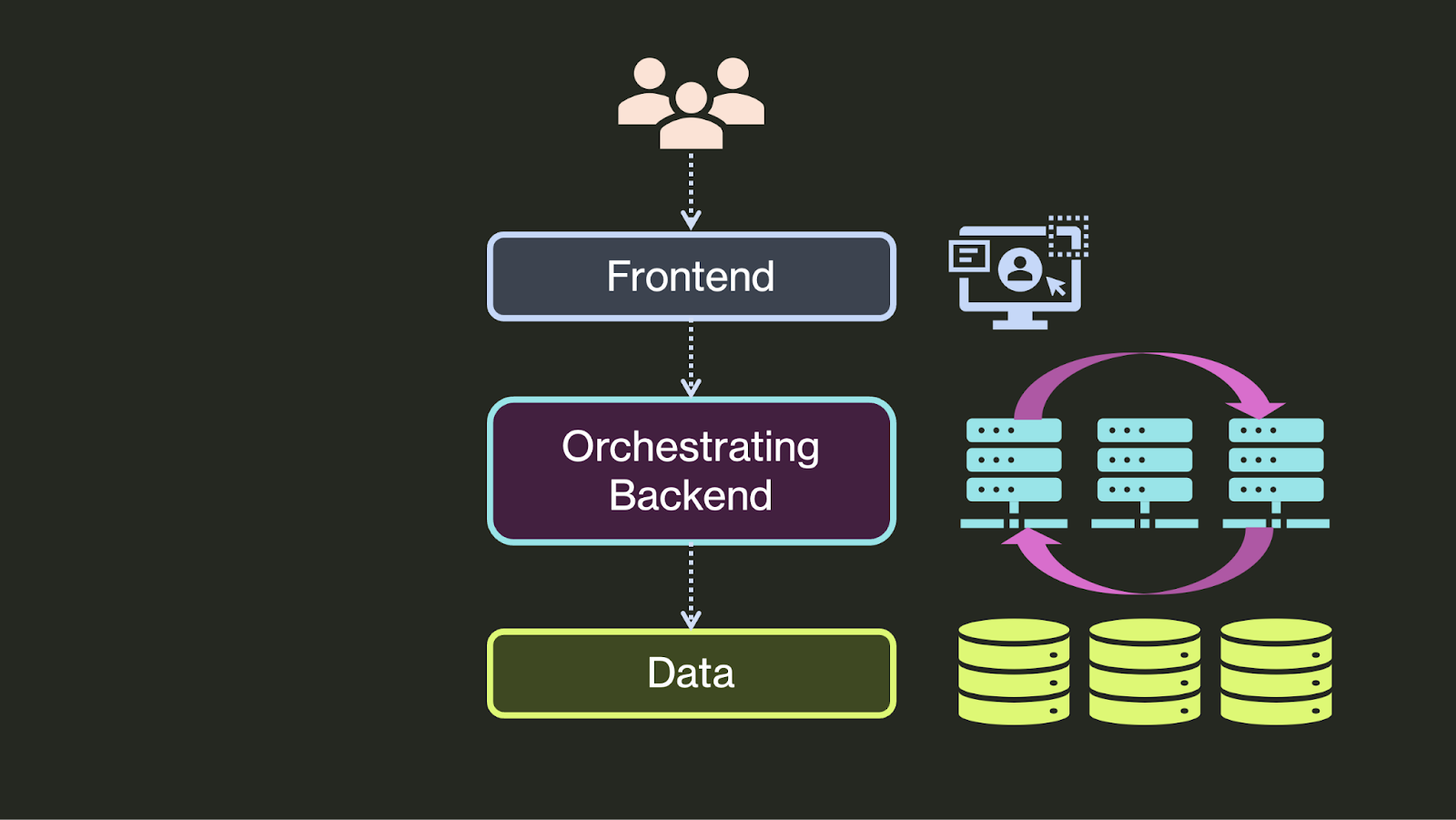
This complexity has created a new problem for application developers: how to coordinate operations in a distributed backend? For example:
- How to atomically perform a set of operations in multiple services, so that all happen or none do?
- How to request a remote service execute a task exactly once?
- How to execute a task asynchronously?
These are difficult challenges to solve in any setting, but are especially hard for a distributed backend because of the possibility of transient failures in any service at any time. Even monolithic backends now face similar challenges, as they increasingly depend on numerous third-party services (e.g. OpenAI for AI capabilities, Stripe for billing, Twilio for messaging, Auth0 for authentication) and must carefully coordinate interactions with them.
To solve these problems, developers have introduced a new application tier: an orchestration tier that coordinates operations across distributed microservices and presents a simple API to the frontend.
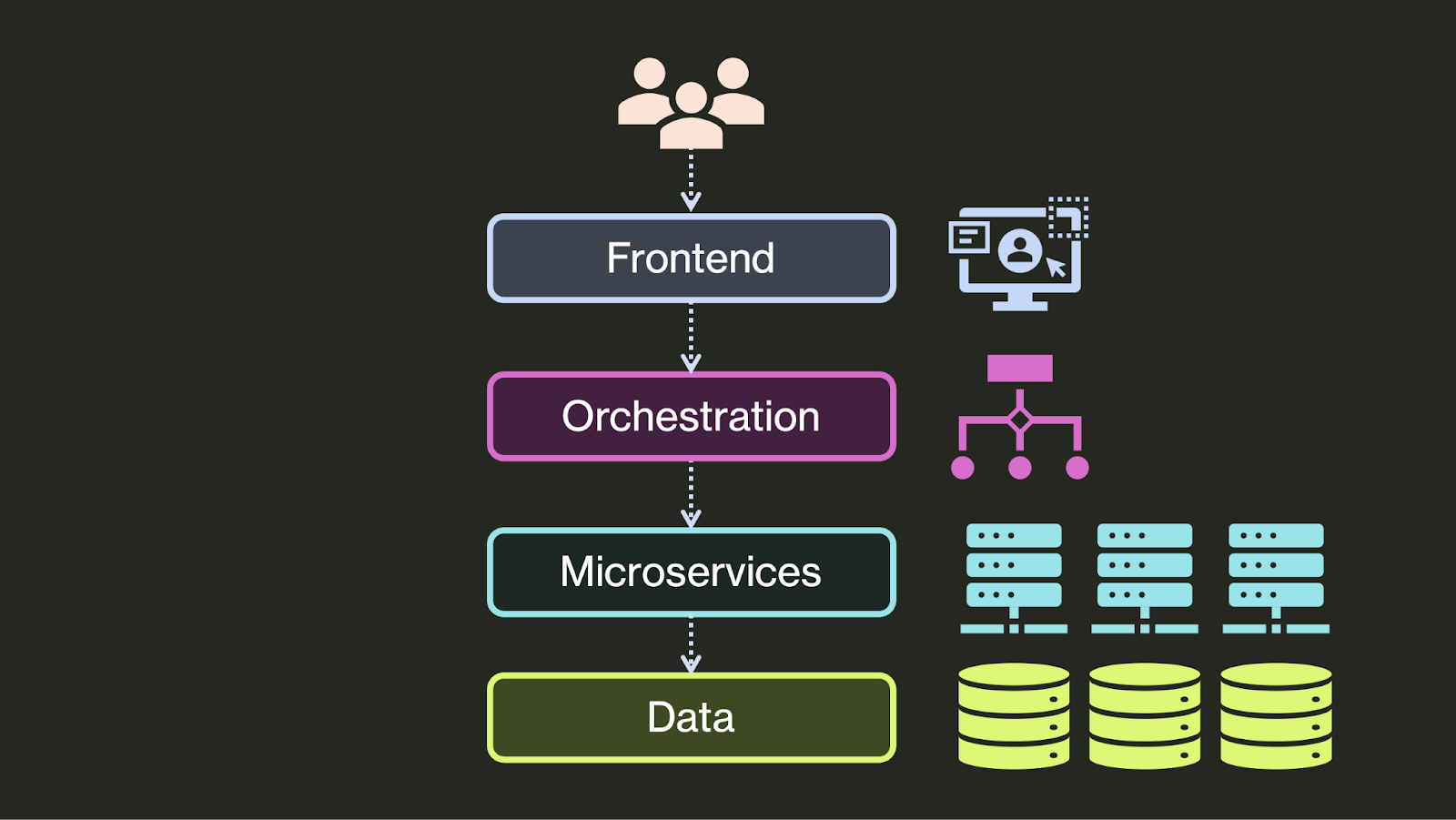
This orchestration tier is primarily responsible for guaranteeing code executes correctly despite failures. For example, an orchestration tier might:
- Guarantee a set of operations are executed atomically by following a saga pattern, retrying transient failures and “backing out” by undoing earlier operations if later operations fail unrecoverably.
- Execute a task exactly-once by submitting it with an idempotency key and retrying in case of transient failure.
- Safely execute an asynchronous task by monitoring its execution and restarting it if it is interrupted.
How to Build a Workflow Orchestration Tier
At this point, developers have been building orchestration tiers for more than a decade. Broadly, there are two classes of orchestration tier. Each has advantages and disadvantages, and most large enterprises use both for different applications.
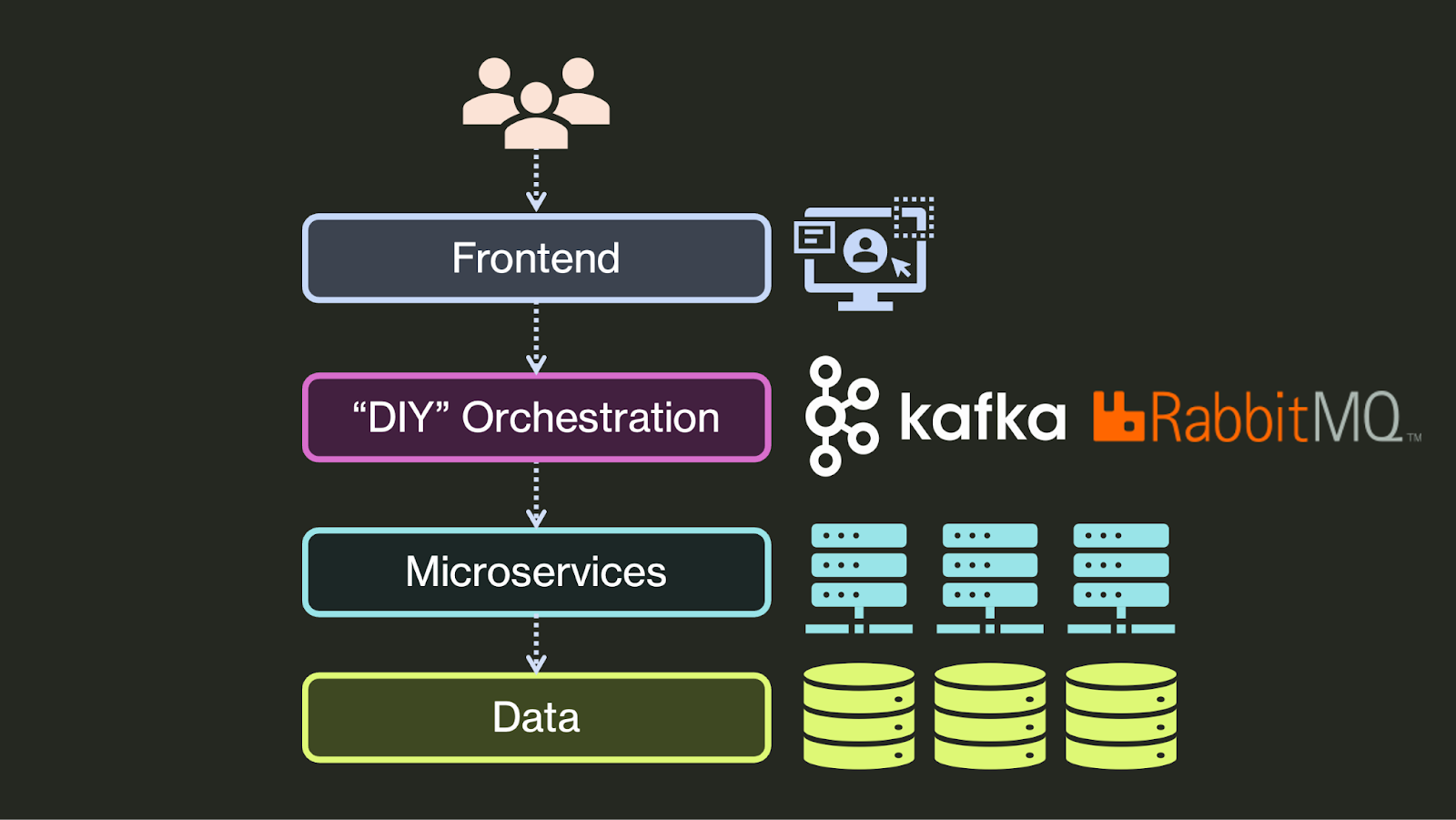
Option 1: Do-It-Yourself
The first class is “Do-It-Yourself” orchestration. Here, developers implement orchestration themselves, often leveraging an event processing system or message broker like Apache Kafka, AWS SQS, or RabbitMQ. For example, for service A to schedule a task in service B, service A would write the task to Kafka, then service B would read the message from Kafka and execute the task. Doing this correctly is hard and requires deep knowledge of the semantics of the underlying system. In this example, service B would have to correctly handle duplicate messages (since Kafka delivers at-least-once) and would have to manage timeouts while processing its task.
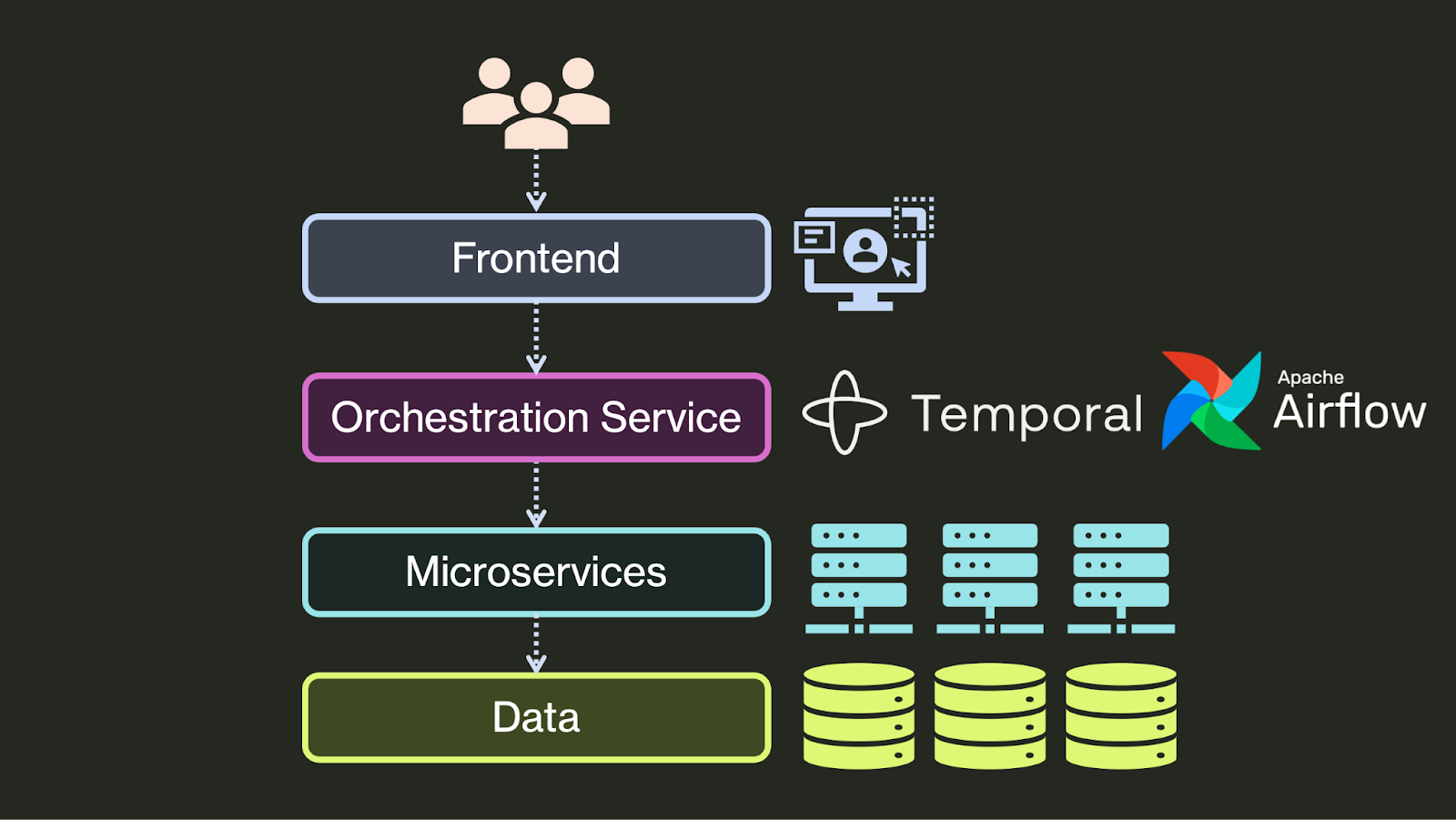
Option 2: Dedicated External Orchestrator (e.g., Temporal)
The second class of orchestration tier are dedicated orchestration systems, which started to emerge in the last few years in response to the complexity of DIY solutions. Most of these use a workflow abstraction, where developers write programs as workflows of tasks. The system durably executes the workflow, retrying individual steps until they succeed and keeping track of the workflow’s progress in a persistent store. Some popular orchestration systems include AWS Step Functions, for AWS operations (especially AWS Lambda functions), Apache Airflow, for data engineering pipelines, and Temporal, for asynchronous backends.
Right now, an orchestration tier seems necessary to manage the complexity of distributed systems. However, neither class is completely satisfactory. DIY solutions are complex and hard to maintain. Orchestration systems are easier to use, but require outsourcing your application’s control flow to an external system, with all the architectural complexity that entails. Additionally, both DIY solutions and orchestration systems typically come with significant performance overhead because of the need for many rounds of communication between the orchestration and backend tiers and because most orchestration solutions are highly asynchronous.
What Comes Next: Embedded Workflow Orchestration
You can’t put the genie back in the bottle. At the technical and organizational scale of modern enterprises, the complexity of orchestrating distributed systems is unavoidable. However, we need better ways of managing that complexity.
The biggest source of complexity comes from the separation of the orchestration and application tiers. Running an application’s control flow on a separate system from its business logic adds friction to every step of developing, testing, and debugging an application. It essentially turns individual applications into distributed microservices, with all the complexity that implies.
To manage this complexity, we believe that any good solution to the orchestration problem should combine the orchestration and application tiers. At DBOS, we’re throwing our hat in the ring by building DBOS Transact (Python, TypeScript, Go, Java, Kotlin): a lightweight orchestration library you can add to any program. Like in existing orchestration systems, you write programs as workflows of steps. For example, here’s a simplified program for performing checkout in an e-commerce service:
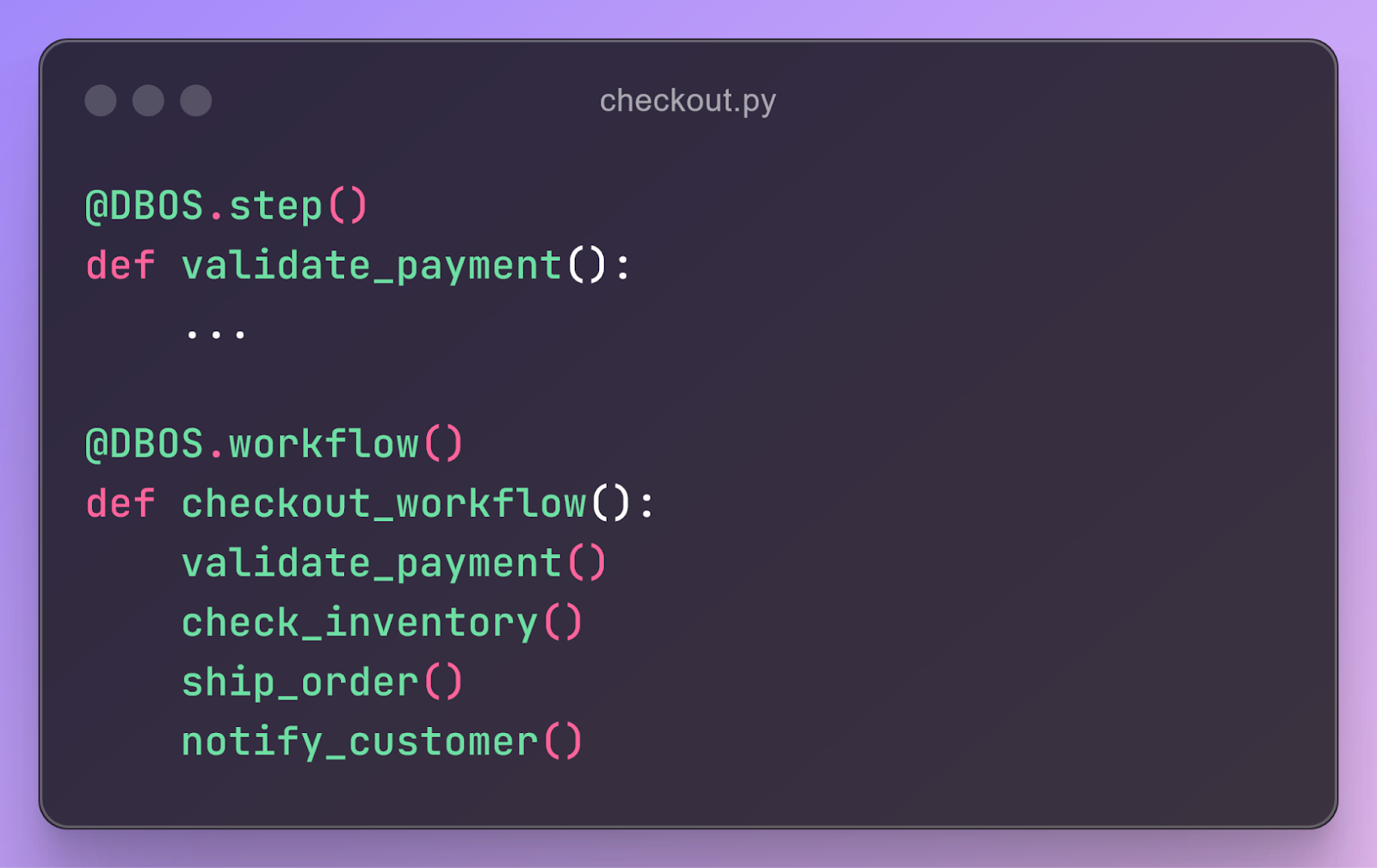
The library (specifically, the DBOS.workflow() and DBOS.step() decorators) wraps your functions with code that orchestrates them. It persists your program’s execution state–which workflows are currently executing and which steps they’ve completed–in a Postgres database.
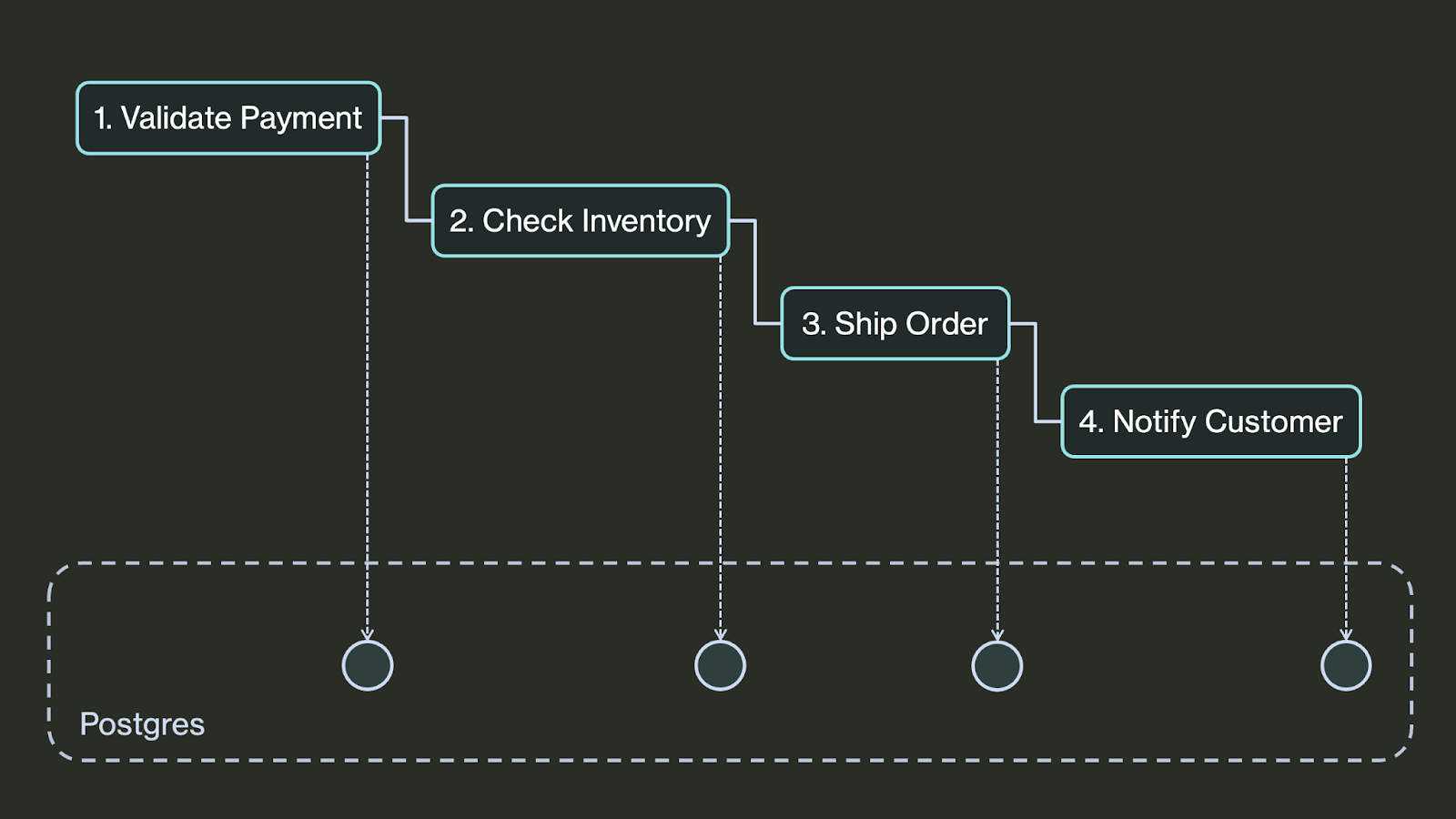
By persisting execution state to a database, a lightweight library can fulfill the primary goal of an orchestration system: guaranteeing code executes correctly despite failures. If a program fails, the library can look up its state in Postgres to figure out what step to take next, retrying transient issues and recovering interrupted executions from their last completed step.
To make this more concrete: imagine the order shipping service experiences an outage. The workflow doesn't cancel paid orders (which would frustrate customers). Instead, it retries with exponential backoff—potentially for hours—until the shipping service recovers. If the checkout service itself crashes or restarts while workflows are waiting, orders aren't lost. The service simply looks up each workflow's state in Postgres and resumes each from where it left off, ensuring customer orders are processed correctly even through multiple system failures.
Implementing orchestration in a library connected to a database means you can eliminate the orchestration tier, pushing its functionality into the application tier (the library instruments your program) and the database tier (your workflow state is persisted to Postgres). This manages the complexity of a distributed world, bringing the complexity of a microservice RPC call or third-party API call closer to that of a regular function call. So once again, applications will have three tiers: